12 Tidy data
12.1 Introduction
"행복한 가정은 다 비슷비슷하다. 모든 불행한 가정은 다 가지각색으로 불행하다." - 레오 톨스토이 "Tidy 데이터셋은 다 비슷비슷하다. 모든 지저분한 데이터들은 다 가지각색으로 지저분하다." - Hadley Wickham
이 chapter에서는, R의 데이터를 organise하는 consistent 방법에 대해서 배울 것이다.
이 구조가 tidy data이다.
너의 데이터를, 이러한 포맷으로 만드는건 선불의upfront 작업을 필요로 한다. 근데 가치가 있는 일임.
이러한 tidy data랑 tidy tools를 잘 쓰면, 데이터를 어떠한 표현에서 다른 표현으로 개조하는데에,
시간을 훨씬 적게 쓰게 될거다. 그리고 그만큼 분석하는데에 시간을 더 쓸 수 있고.
이 단원은 tidy data에 대한 실용적인 소개와 tidyr에 딸려있는 도구들에 대해 설명
12.1.1 Prerequisites
tidyr이라는 패키지를 사용할 것인데, 이건 tidyverse의 코어 중 하나다.
그래서 tidyverse만 로드하면 된다.
library(tidyverse)
12.2 Tidy data
같은 데이터를 여러가지 방법으로 표현represent할 수 있다.
다음 예는 같은 데이터를 4가지 다른 방법으로 organise하는 것을 보여준다.
각 데이터셋은 4가지 변수country, year, population, cases에 대한 같은 값을 보여주지만,
다른 방법으로 organise되어있다.
table1
## # A tibble: 6 x 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583
table2
## # A tibble: 12 x 4
## country year type count
## <chr> <int> <chr> <int>
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583
table3
## # A tibble: 6 x 3
## country year rate
## * <chr> <int> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583
# 2개의 tibble에 나누어서 표현되어 있는,
table4a
## # A tibble: 3 x 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766
table4b
## # A tibble: 3 x 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 19987071 20595360
## 2 Brazil 172006362 174504898
## 3 China 1272915272 1280428583
다 같은 데이터에 대한 표현인데, 다 똑같이 사용하기 쉬운건 아니다.
하나의 데이터셋인, 'tidy 데이터셋'이, tidyverse에서 작업하기 훨씬 쉽다.
dataset을 tidy하게 만드는 3가지 interrelated rules가 있다.
1. 각 변수는 항상 own 칼럼을 가져야 한다.
2. 각 관측치는 항상 own 행을 가져야 한다.
3. 각 값은 항상 own 셀을 가져야 한다.
Figure 12.1가 이걸 visually하게 보여준다. 
3개의 룰 : 변수는 칼럼에, 관측치는 행에, 값은 cell에.
이 3가지 룰은 interrelated되어있다. 왜냐하면 3개 중에 2개만 갖는 것은 불가능하기 때문.
그래서, 다음과 같이 더 간단한 실용적인 룰들을 정할 수 있다.
- 각 데이터셋을 tibble에다 넣어라.
- 각 변수를 칼럼에다 넣어라.
이 예시에서,table1만이 tidy하다. 각 칼럼이 변수인 유일한 표현이다.
왜 tidy하게 만들어야 되냐? 2가지 장점이 있다.
1. 데이터를 저장하는데 있어, one consistent way를 정하는거에 일반적인 장점이 있다.
만약 너가 일관성 있는 데이터 구조를 갖고 있다면, underlying하는 통일성이 있어서, 그걸 다루는 툴들을 배우는게 쉽다.
- 변수를 칼럼에다 놓으면, 특정한 장점이 있다. 이게 R의 벡터화시키는 속성을 빛나게 한다.
mutate와 summary functions에서 배웠듯이, 거의 모든 R built-in 함수들은 벡터의 값들과 연동.
그래서, tidy data를 transforming하는게 특히나 자연스럽게 느껴지게 된다.
tidyverse에 있는 dplyr, ggplot2 그리고 다른 패키지들은 tidy data와 작업할 수 있게끔 디자인되었다.
table1과 어떻게 작업할 수 있는지, 예들이 있음.
# rate per 10,000을 구하고 싶다면,
table1 %>%
mutate(rate = cases / population * 10000)
## Warning: The `printer` argument is deprecated as of rlang 0.3.0.
## This warning is displayed once per session.
## # A tibble: 6 x 5
## country year cases population rate
## <chr> <int> <int> <int> <dbl>
## 1 Afghanistan 1999 745 19987071 0.373
## 2 Afghanistan 2000 2666 20595360 1.29
## 3 Brazil 1999 37737 172006362 2.19
## 4 Brazil 2000 80488 174504898 4.61
## 5 China 1999 212258 1272915272 1.67
## 6 China 2000 213766 1280428583 1.67
# cases per year을 구하고 싶다면
table1 %>%
count(year, wt = cases)
## # A tibble: 2 x 2
## year n
## <int> <int>
## 1 1999 250740
## 2 2000 296920
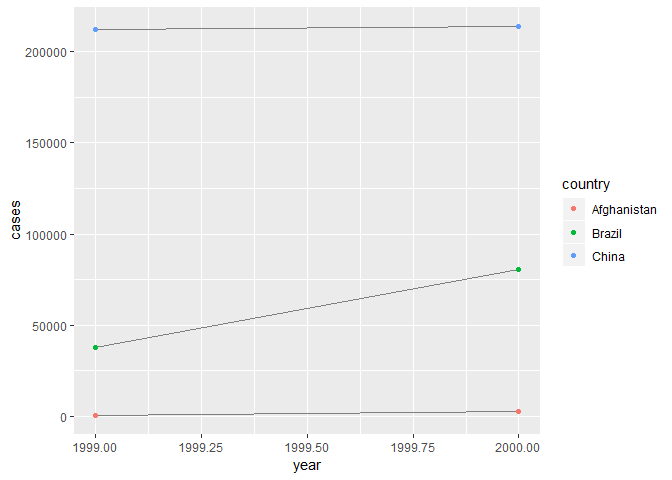
# visualise changes over time을 하고 싶다면
ggplot(table1, aes(year, cases)) +
geom_line(aes(group = country), color = "grey50") +
geom_point(aes(colour = country))
12.2.1 Exercises
12.3 Spreading and gathering
tidy data의 원리는 너무나 명확해서, 가끔 너는 이런 생각을 할거다.
안 그런 데이터가 있나? 그러나 대부분이 untidy하다. 2가지 주요 이유가 있다.
- 대부분의 사람들이 tidy data의 원리를 잘 알고 있는 건 아니기 때문에, 혼자 힘으로 이걸 derive하기는 힘들다.
데이터와 작업하는데 많은 시간을 쏟아부은 사람이 아닌 이상ㅇㅇ - 보통 데이터라는게 분석을 위해서가 아니라 다른 목적을 위해서 organise되었기 때문.
예를 들어서, 데이터는 보통 entry를 최대한 쉽게 만드려고 organise되었다.
이 말인즉슨, 실제 분석을 위해서는, tidying 작업이 필요하다는거.
첫 번째 단계는 무엇이 변수고 무엇이 관측치인지를 판단하는 것.
가끔은 이게 쉬운데, 때로는 데이터를 구성한 사람과 상의consult할 필요가 있다.
두 번째 단계는, 2가지 일반적인common 문제중 하나를 풀어야 한다.
1. 하나의 변수가 여러 개의 칼럼에 퍼져있다.spread across
2. 하나의 관측치가 여러 개의 행에 퍼져있다.scattered across
보통은 데이터셋이 둘 중 하나의 문제점만 가지고 있는데, 재수 없으면 둘 다 있다.
이 문제를 해결하기 위해서는, tidyr에서 가장 중요한 2개의 함수가 필요하다.
gather()과 spread()
12.3.1 Gathering
데이터셋의 흔한 문제는 칼럼이름이 변수이름이 아니라는 거. 그럼 변수이름이 아니고 뭐냐?
변수값. 칼럼이름이 변수값.
table4a를 봐보자. 칼럼 이름이 1999이고 2000이다. year이라는 변수의 '값'을 나타내고 있다.
그리고 각 행이 2개의 관측치를 표시하고 있다. 하나가 아니고.
table4a
## # A tibble: 3 x 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766
이러한 데이터셋을 tidy하기 위해서는, 칼럼들을 한 쌍의 변수로 gather할 필요가 있다.
이 작업을 묘사하기 위해서 3개의 parameters가 필요하다.
- set of columns가 변수가 아닌 값을 나타내고represent 있다.
이 예에서는,1999과2000이라는 칼럼들. - '칼럼이름들을 구성하고 있는 값'들의 변수 이름.
key라고 하는데, 여기서는year다.
(1999과2000이라는 변수값을 ->year라는 변수이름으로) - 셀들에 퍼져있는 값들을 변수이름으로.
value라고 하는데, 여기서는 number ofcases다.
(745, 2666라는 값들을 ->cases라는 변수이름으로)
이제 이 parameters들, 1999, 2000, years, cases들을 gather()로 호출한다.
table4a %>%
gather(`1999`, `2000`, key = "year", value = "cases")
## # A tibble: 6 x 3
## country year cases
## <chr> <chr> <int>
## 1 Afghanistan 1999 745
## 2 Brazil 1999 37737
## 3 China 1999 212258
## 4 Afghanistan 2000 2666
## 5 Brazil 2000 80488
## 6 China 2000 213766
dplyr::select()에서 했던 스타일로 칼럼들을 gather한 것을 볼 수 있다.
이 경우에는 칼럼이 2개 뿐이여서, 개별적으로 리스트를 했다.
그리고 "1999"랑 "2000"은 non-syntactic names라서, backtick으로 감싸놓은 것을 볼 수 있다.
칼럼들을 select하는게 기억이 안 난다면, select를 다시 봐보자.
최종 결과물을 보면, gathered된 칼럼들은 사라지고, 새로운 key와 value라는 칼럼들을 얻었다.
반면에, 원래 변수들과의 관계는 보존되어 있다.
Figure 12.2에 이 관계가 나타나있다. 
table4b도 비슷한 방법으로 gather()할 수 있다.
다른 점은, cell에 cases가 아닌 population이 저장되어 있는 것 뿐.
table4b %>%
gather(`1999`, `2000`, key = "year", value = "population")
## # A tibble: 6 x 3
## country year population
## <chr> <chr> <int>
## 1 Afghanistan 1999 19987071
## 2 Brazil 1999 172006362
## 3 China 1999 1272915272
## 4 Afghanistan 2000 20595360
## 5 Brazil 2000 174504898
## 6 China 2000 1280428583
table4a와 table4b를 tided된 하나의 tibble로 combine하기 위해서, dplyr::left_join()을 쓴다.
tidy4a <- table4a %>%
gather(`1999`, `2000`, key = "year", value = "cases")
tidy4b <- table4b %>%
gather(`1999`, `2000`, key = "year", value = "population")
left_join(tidy4a, tidy4b)
## Joining, by = c("country", "year")
## # A tibble: 6 x 4
## country year cases population
## <chr> <chr> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Brazil 1999 37737 172006362
## 3 China 1999 212258 1272915272
## 4 Afghanistan 2000 2666 20595360
## 5 Brazil 2000 80488 174504898
## 6 China 2000 213766 1280428583
이러한 join은 relational data에서 배우게 될 것이다.
그러니깐 gathering은, 칼럼에 변수가 있어야되는데 값이 있을 때 쓰는 것.
12.3.2 Spreading
spreading은 gathering의 반대다. 관측치들이 multiple 행들에 퍼져있을 때 쓴다.
예를 들어서, table2를 보자.
관측치는 한 해의 한 국가인데, 각 관측치들이 2줄에 걸쳐 퍼져 있는 걸 볼 수 있다.
이걸 tidy하기 위해서, 먼저 gather()과 비슷한 방법으로 분석한다. 하지만 이번에 2개의 params만 필요.
1. 변수 이름을 가지고 있는 칼럼. key 칼럼. 여기서는 type
2. 다양한 변수로부터 나온 값들을 가지고 있는 칼럼. value 칼럼. 여기서는 count
이걸 알아냈으면, spread()를 이용하자.
어떻게 작동하고 있는건지는 Figure 12.3으로 볼 수 있다. 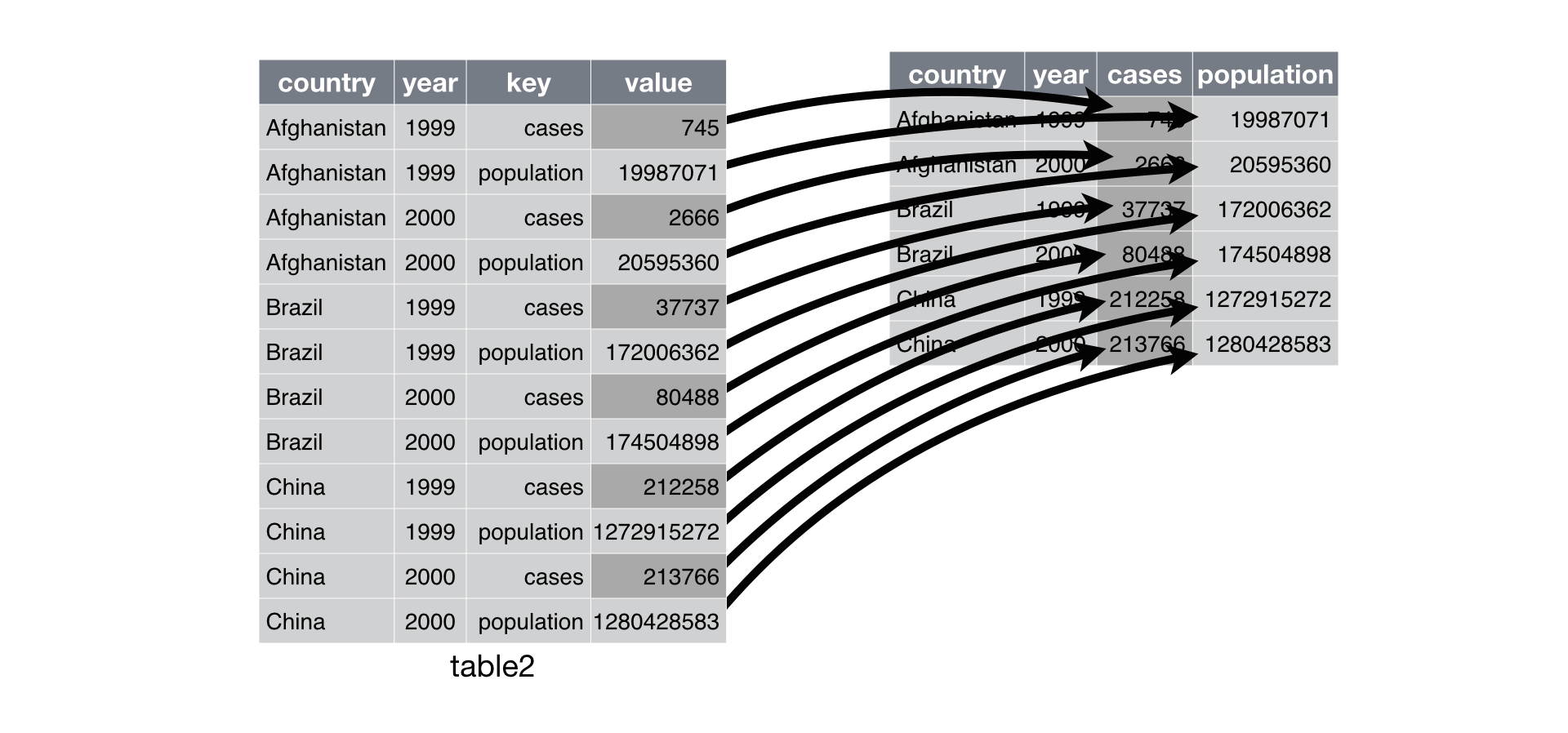
table2 %>%
spread(key = type, value = count)
## # A tibble: 6 x 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583
공통된 key와 value라는 arguments에서 볼 수 있듯이, spread()와 gather()는 보충관계다.
gather()는 wide tables를 좁고 길게 만들고, spread()는 long tables를 짧고 넓게 만든다.
그러니깐 spreading은, 관측치들이 2줄에 걸쳐 퍼져있을 때, key와 value를 이용해서.
12.3.3 Exercises
12.4 Separating and uniting
이 때까지는 table2, table4를 tidy하는 법에 대해 배웠다. table3은 안 했다.
얘는 약간 다른 문제를 가지고 있기 때문. 얘는 하나의 칼럼이 2개의 변수를 가지고 있다.
rate라는 칼럼이 cases와 population라는 변수를 가지고 있음.
이 문제를 해결하기 위해서, separate()라는 함수가 필요하다. 이것의 complement인 unite()도 배울 것.
이건 만약 하나의 변수가 multiple columns에 퍼져있을 때 쓰는 것.
12.4.1 Separate
separate()는 하나의 칼럼을 끄집어내서 여러 개의 칼럼에다가 넣는다.
이 경우에 있어서는, rate에서 cases와 population을.
식별자separator character를 기준으로 쪼개서. table3을 보자.
rate란 칼럼이 cases와 population이라는 변수를 가지고 있다. 그리고 이걸 쪼개야 됨.
separate()는 쪼개질 칼럼의 이름, 그리고 쪼개진 걸 어떻게 받을건지, 이름을 정해줘야한다.
Figure 12.4에 어떤 식으로 작동하고 있는지가 나와있다.
table3 %>%
separate(rate, into = c("cases", "population"))
## # A tibble: 6 x 4
## country year cases population
## <chr> <int> <chr> <chr>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583

디폴트로, separate()는 알파벳이나 숫자가 아닌 문자를 기준으로 값들을 쪼개준다.
만약에 지정해주고 싶다면, separate()의 sep 인자argument로 넘겨줄 수 있다.
예를 들어서, 위의 코드를 다음과 같이 쓸 수 있다.
table3 %>%
separate(rate, into = c("cases", "population"), sep = "/")
## # A tibble: 6 x 4
## country year cases population
## <chr> <int> <chr> <chr>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583
(형식적으로, sep은 정규식이다. 이건 strings에서 배우게 된다.)
잘 보면, 이걸 하고 난 다음 얻는 tibble은 cases와 population값들을 캐릭터로 받았다.
이건 separate()의 디폴트가 그렇기 때문.
원래 칼럼의 타입을 그대로 남겨둔다. 원래 rate 칼럼이 character라...
이걸 숫자로 인식하도록 하려면,
table3 %>%
separate(rate, into = c("cases", "population"), convert = TRUE)
## # A tibble: 6 x 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583
sep 인자 부분에다가 숫자나 문자가 아닌 거 말고, 숫자를 넣을 수도 있다.
숫자는 포지션으로 인식할 것이다. 양수는 왼쪽에서부터 시작하고, 음수는 오른쪽에서부터 시작.
당연하게, 숫자를 쓸 때는, sep에 넣을 숫자는 쪼갤 문자의 길이보다 하나 적어야.
이걸 이용해서, 저 year부분을 century와 year로 쪼개보자.
table3 %>%
separate(year, into = c("century", "year"), sep = 2)
## # A tibble: 6 x 4
## country century year rate
## <chr> <chr> <chr> <chr>
## 1 Afghanistan 19 99 745/19987071
## 2 Afghanistan 20 00 2666/20595360
## 3 Brazil 19 99 37737/172006362
## 4 Brazil 20 00 80488/174504898
## 5 China 19 99 212258/1272915272
## 6 China 20 00 213766/1280428583
12.4.2 Unite
unite()는 separate()의 반대다. 이건 여러 개의 칼럼들을 하나의 칼럼으로 합친다.
separate()보다는 훨씬 덜 쓸 일이 없겠지만, 알아두면 좋음.
위에서 century와 year로 쪼갰던 걸 unite()로 합칠수도 있다. 위에 것을 table5로 저장해뒀다.
물론 unite()도 select()와 비슷한 문법으로.
table5 %>%
unite(new, century, year)
## # A tibble: 6 x 3
## country new rate
## <chr> <chr> <chr>
## 1 Afghanistan 19_99 745/19987071
## 2 Afghanistan 20_00 2666/20595360
## 3 Brazil 19_99 37737/172006362
## 4 Brazil 20_00 80488/174504898
## 5 China 19_99 212258/1272915272
## 6 China 20_00 213766/1280428583
디폴트로 얘는 합칠 때 _를 넣어서 합쳐준다. 하지만 여기서 우리는 식별자를 원하지 않으니깐 ""로.
table5 %>%
unite(new, century, year, sep = "")
## # A tibble: 6 x 3
## country new rate
## <chr> <chr> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583
12.4.3 Exercises
12.5 Missing values
데이터셋의 표현을 바꾸는 건, missing 값들의 미묘함에 대한 문제를 불러 일으킨다.
놀랍게도, 한 가지가 아닌, 두 가지 방법 중 하나로 missing이 일어난다.
1. explicitly. NA로 표현
2. implicitly. 데이터에는 나타나지 않는 것.
이걸 간단한 데이터셋으로 표현해보자.
stocks <- tibble(
year = c(2015, 2015, 2015, 2015, 2016, 2016, 2016),
qtr = c( 1, 2, 3, 4, 2, 3, 4),
return = c(1.88, 0.59, 0.35, NA, 0.92, 0.17, 2.66)
)
stocks
## # A tibble: 7 x 3
## year qtr return
## <dbl> <dbl> <dbl>
## 1 2015 1 1.88
## 2 2015 2 0.59
## 3 2015 3 0.35
## 4 2015 4 NA
## 5 2016 2 0.92
## 6 2016 3 0.17
## 7 2016 4 2.66
2015년 4분기는 NA라고 되어있으니, explicitly missing,
2016년 1분기는 데이터셋에는 나타나지 않으니, implicitly missing이다.
저자는 불교 선禪의 개념으로 차이를 설명한다.
explicit missing은 부재의 존재, implicit은 존재의 부재.(;;)
데이터셋이 어떻게 표현되느냐에 따라, implicit한 값들을 explicit하게 만들할 수 있다.
예를 들어서, year라는 칼럼을 만들어서, implicit한 값을 explicit하게 만들 수 있음.
stocks %>%
spread(year, return)
## # A tibble: 4 x 3
## qtr `2015` `2016`
## <dbl> <dbl> <dbl>
## 1 1 1.88 NA
## 2 2 0.59 0.92
## 3 3 0.35 0.17
## 4 4 NA 2.66
그런데 경우에 따라선, 이러한 explicit missing이 중요하지 않을 수 있기 때문에,
gather()에서의 na.rm = T를 이용해서 explicit한 missing을 implicit하게 만들 수 있다.
stocks %>%
spread(year, return) %>%
gather(year, return, `2015`:`2016`, na.rm = TRUE)
## # A tibble: 6 x 3
## qtr year return
## <dbl> <chr> <dbl>
## 1 1 2015 1.88
## 2 2 2015 0.59
## 3 3 2015 0.35
## 4 2 2016 0.92
## 5 3 2016 0.17
## 6 4 2016 2.66
다른 중요한 툴로, explicit한 missing values를 만들 수 있다. complete()
stocks %>%
complete(year, qtr)
## # A tibble: 8 x 3
## year qtr return
## <dbl> <dbl> <dbl>
## 1 2015 1 1.88
## 2 2015 2 0.59
## 3 2015 3 0.35
## 4 2015 4 NA
## 5 2016 1 NA
## 6 2016 2 0.92
## 7 2016 3 0.17
## 8 2016 4 2.66
complete()는 모든 칼럼의 셋을 받아서, 가능한 모든 조합들을 찾음.
그리고 난 다음에 기존의 데이터셋의 값들을 다 받아서 넣어놓고, 필요한 곳에 NA를 explicit하게 넣는다.
missing values에 대한 작업을 할 때, 니가 알아야할 다른 중요한 툴이 있다.
가끔, 데이터 소스가 누락된 건, 이전에 입력된 값을 이월시켜서 쓴다는 걸 의미할 때가 있다.
이건 fill()을 이용해서 채울 수 있다. 가장 최근의 값들로 missing을 채운다는 걸 의미.
treatment <- tribble(
~ person, ~ treatment, ~response,
"Derrick Whitmore", 1, 7,
NA, 2, 10,
NA, 3, 9,
"Katherine Burke", 1, 4
)
treatment
## # A tibble: 4 x 3
## person treatment response
## <chr> <dbl> <dbl>
## 1 Derrick Whitmore 1 7
## 2 <NA> 2 10
## 3 <NA> 3 9
## 4 Katherine Burke 1 4
이렇게 되어있는 걸,
treatment %>%
fill(person)
## # A tibble: 4 x 3
## person treatment response
## <chr> <dbl> <dbl>
## 1 Derrick Whitmore 1 7
## 2 Derrick Whitmore 2 10
## 3 Derrick Whitmore 3 9
## 4 Katherine Burke 1 4
12.5.1 Exercises
12.6 Case Study
이 챕터를 끝내기 전에, 배운걸 다 써서 현실적인 data tidy 문제를 해결해보자.
tidyr::who 데이터셋은 결핵tuberculosis(TB) 케이스들을 가지고 있다.
year, country, age, gender 그리고 diagnosis method를 갖고 있음.
2014 World Health Organization Global Tuberculosis Report 에서 데이터를 얻었으며,
http://www.who.int/tb/country/data/download/en/에서 접근할 수 있다.
이 데이터셋에는 병리학적epidemiological 정보들이 풍부한데, 제공된 형식으로는 작업하기가 힘들다.
who
## # A tibble: 7,240 x 60
## country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534
## <chr> <chr> <chr> <int> <int> <int> <int>
## 1 Afghan~ AF AFG 1980 NA NA NA
## 2 Afghan~ AF AFG 1981 NA NA NA
## 3 Afghan~ AF AFG 1982 NA NA NA
## 4 Afghan~ AF AFG 1983 NA NA NA
## 5 Afghan~ AF AFG 1984 NA NA NA
## 6 Afghan~ AF AFG 1985 NA NA NA
## 7 Afghan~ AF AFG 1986 NA NA NA
## 8 Afghan~ AF AFG 1987 NA NA NA
## 9 Afghan~ AF AFG 1988 NA NA NA
## 10 Afghan~ AF AFG 1989 NA NA NA
## # ... with 7,230 more rows, and 53 more variables: new_sp_m3544 <int>,
## # new_sp_m4554 <int>, new_sp_m5564 <int>, new_sp_m65 <int>,
## # new_sp_f014 <int>, new_sp_f1524 <int>, new_sp_f2534 <int>,
## # new_sp_f3544 <int>, new_sp_f4554 <int>, new_sp_f5564 <int>,
## # new_sp_f65 <int>, new_sn_m014 <int>, new_sn_m1524 <int>,
## # new_sn_m2534 <int>, new_sn_m3544 <int>, new_sn_m4554 <int>,
## # new_sn_m5564 <int>, new_sn_m65 <int>, new_sn_f014 <int>,
## # new_sn_f1524 <int>, new_sn_f2534 <int>, new_sn_f3544 <int>,
## # new_sn_f4554 <int>, new_sn_f5564 <int>, new_sn_f65 <int>,
## # new_ep_m014 <int>, new_ep_m1524 <int>, new_ep_m2534 <int>,
## # new_ep_m3544 <int>, new_ep_m4554 <int>, new_ep_m5564 <int>,
## # new_ep_m65 <int>, new_ep_f014 <int>, new_ep_f1524 <int>,
## # new_ep_f2534 <int>, new_ep_f3544 <int>, new_ep_f4554 <int>,
## # new_ep_f5564 <int>, new_ep_f65 <int>, newrel_m014 <int>,
## # newrel_m1524 <int>, newrel_m2534 <int>, newrel_m3544 <int>,
## # newrel_m4554 <int>, newrel_m5564 <int>, newrel_m65 <int>,
## # newrel_f014 <int>, newrel_f1524 <int>, newrel_f2534 <int>,
## # newrel_f3544 <int>, newrel_f4554 <int>, newrel_f5564 <int>,
## # newrel_f65 <int>
이게 전형적인 현실적인 데이터셋의 예다.
보다시피 쓸모없는 칼럼들도 있고, 이상한 변수들이 코드되어 있고, 결측값들이 많다.
한 마디로 말해서, who는 messy하다.
그리고 이걸 tidy하기 위해서는 여러 스텝들이 필요하다.
dplyr와 마찬가지로, tidyr도 하나의 함수가 하나의 작업을 잘 하도록 설계되었다.
그래서 현실에서는 pipeline(%>%)을 여러 줄 이용해서 작업해야 할 것이다.
시작점으로 가장 좋은 것은, 변수가 아닌 칼럼들은 gather하는 것이다.
뭐가 있는지 한 번 살펴보자.
country,iso2,iso3는 쓸데없이 어떤 나라인지를 명시해놓았다.year은 확실히 변수- 다른 칼럼들은 뭔지 아직 모르지만, 변수 이름의 구조를 보았을 때(
new_sp_m014,new_ep_m014,new_ep_f014),
변수가 아닌 값이라고 생각해볼 수 있다.
그래서 new_sp_m014 부터 newrel_f65까지의 칼럼들을 gather하면 된다.
이 값들이 무엇을 표현하는지는 모르지만, 이것들의 일반적인 이름으로 "key"를 주겠다.
그리고 각 cell이 한 번 일어났다는 것을 표현하는 것이기 때문에, 이걸 cases라는 변수로 둘 것이다.
마지막으로, 이 표현에서는 결측값들이 많기 때문에, na.rm을 사용해서, 존재하는 것들에만 집중할 것이다.
who1 <- who %>%
gather(new_sp_m014:newrel_f65, key = "key", value = "cases", na.rm = TRUE)
who1
## # A tibble: 76,046 x 6
## country iso2 iso3 year key cases
## <chr> <chr> <chr> <int> <chr> <int>
## 1 Afghanistan AF AFG 1997 new_sp_m014 0
## 2 Afghanistan AF AFG 1998 new_sp_m014 30
## 3 Afghanistan AF AFG 1999 new_sp_m014 8
## 4 Afghanistan AF AFG 2000 new_sp_m014 52
## 5 Afghanistan AF AFG 2001 new_sp_m014 129
## 6 Afghanistan AF AFG 2002 new_sp_m014 90
## 7 Afghanistan AF AFG 2003 new_sp_m014 127
## 8 Afghanistan AF AFG 2004 new_sp_m014 139
## 9 Afghanistan AF AFG 2005 new_sp_m014 151
## 10 Afghanistan AF AFG 2006 new_sp_m014 193
## # ... with 76,036 more rows
이러고나면, 새로운 key 칼럼의 수를 세어봄으로써, 값들의 구조에 대한 힌트를 좀 얻을 수 있다.
who1 %>%
count(key)
## # A tibble: 56 x 2
## key n
## <chr> <int>
## 1 new_ep_f014 1032
## 2 new_ep_f1524 1021
## 3 new_ep_f2534 1021
## 4 new_ep_f3544 1021
## 5 new_ep_f4554 1017
## 6 new_ep_f5564 1017
## 7 new_ep_f65 1014
## 8 new_ep_m014 1038
## 9 new_ep_m1524 1026
## 10 new_ep_m2534 1020
## # ... with 46 more rows
이걸 직접 parse해봄으로써 어떤 의미를 갖고 있는지 직접 알아볼 수 있지만,
답을 알려주겠다. 어떤 의미냐면,
-
처음 3개의 단어는 새로운 결핵인지 이전의 결핵인지를 알려준다.
근데 이 데이터셋에서는, 사실 모든 케이스가 new 케이스다. -
다음 2개 단어는 결핵의 타입을 알려준다.
rel은 재발relapse한 것.
ep는 폐 외부extrapulmonary의 케이스.
sn은 폐를 진찰해서는 알 수 없었던 케이스. 음성반응smear negative
sp는 폐를 진찰해서 알 수 있었던 케이스. 양성반응smear positive -
6번째 단어는 결핵 환자의 성별을 알려준다. 남성(
m)인지 여성(f)인지. -
마지막 숫자들은 age group을 알려준다. 7개로 나누어져있는데,
-
014= 0 - 14살 1524= 14 - 24살2534= 25 - 34살3544= 35 - 44살4554= 45 - 54살5564= 55 - 64살65= 65살 이상
그리고 또 에러도 고쳐야된다.
이름이 새로운 케이스에 대해 재발을 한 경우라면, new_rel 이렇게 되어야 하는데, newrel 이렇게 되어있다.
(여기서는 알아차리기가 힘든데 안 고쳐놓으면 계속 에러가 발생한다. 보통 EDA를 통해서 알아차리지.)
strings에서 str_replace()에 대해 배우게 될 건데, 기본적인 아이디어는 간단하다.
"newrel"이라는 캐릭터를 "new_rel"로 바꾸는 것이다.
이러면 변수 이름들을 일관성consistent 있게 만들 수 있다.
who2 <- who1 %>%
mutate(key = stringr::str_replace(key, "newrel", "new_rel"))
who2
## # A tibble: 76,046 x 6
## country iso2 iso3 year key cases
## <chr> <chr> <chr> <int> <chr> <int>
## 1 Afghanistan AF AFG 1997 new_sp_m014 0
## 2 Afghanistan AF AFG 1998 new_sp_m014 30
## 3 Afghanistan AF AFG 1999 new_sp_m014 8
## 4 Afghanistan AF AFG 2000 new_sp_m014 52
## 5 Afghanistan AF AFG 2001 new_sp_m014 129
## 6 Afghanistan AF AFG 2002 new_sp_m014 90
## 7 Afghanistan AF AFG 2003 new_sp_m014 127
## 8 Afghanistan AF AFG 2004 new_sp_m014 139
## 9 Afghanistan AF AFG 2005 new_sp_m014 151
## 10 Afghanistan AF AFG 2006 new_sp_m014 193
## # ... with 76,036 more rows
각 코드의 값들을 separate()를 이용해서 분리separate할 수 있다.
먼저, 밑줄(_)을 기준으로 코드를 스플릿.
who3 <- who2 %>%
separate(key, c("new", "type", "sexage"), sep = "_")
who3
## # A tibble: 76,046 x 8
## country iso2 iso3 year new type sexage cases
## <chr> <chr> <chr> <int> <chr> <chr> <chr> <int>
## 1 Afghanistan AF AFG 1997 new sp m014 0
## 2 Afghanistan AF AFG 1998 new sp m014 30
## 3 Afghanistan AF AFG 1999 new sp m014 8
## 4 Afghanistan AF AFG 2000 new sp m014 52
## 5 Afghanistan AF AFG 2001 new sp m014 129
## 6 Afghanistan AF AFG 2002 new sp m014 90
## 7 Afghanistan AF AFG 2003 new sp m014 127
## 8 Afghanistan AF AFG 2004 new sp m014 139
## 9 Afghanistan AF AFG 2005 new sp m014 151
## 10 Afghanistan AF AFG 2006 new sp m014 193
## # ... with 76,036 more rows
근데 모든 케이스들이 new니깐, new 칼럼을 그냥 drop시켜도 될 것이다.
칼럼들을 drop하는김에, iso2, iso3 칼럼도 쓸모없으니깐 그냥 drop하자.
who3 %>%
count(new)
## # A tibble: 1 x 2
## new n
## <chr> <int>
## 1 new 76046
who4 <- who3 %>%
select(-new, -iso2, iso3)
이제 sexage라는걸 sex와 age로 분리separate하자.
who5 <- who4 %>%
separate(sexage, c("sex", "age"), sep = 1)
who5
## # A tibble: 76,046 x 7
## country iso3 year type sex age cases
## <chr> <chr> <int> <chr> <chr> <chr> <int>
## 1 Afghanistan AFG 1997 sp m 014 0
## 2 Afghanistan AFG 1998 sp m 014 30
## 3 Afghanistan AFG 1999 sp m 014 8
## 4 Afghanistan AFG 2000 sp m 014 52
## 5 Afghanistan AFG 2001 sp m 014 129
## 6 Afghanistan AFG 2002 sp m 014 90
## 7 Afghanistan AFG 2003 sp m 014 127
## 8 Afghanistan AFG 2004 sp m 014 139
## 9 Afghanistan AFG 2005 sp m 014 151
## 10 Afghanistan AFG 2006 sp m 014 193
## # ... with 76,036 more rows
이제 who 데이터셋은 tidy해졌다!
각 단계를 한 번씩 보여줬다. 결과물을 따로 따로 저장해가면서,
뭐 물론 실전에서는 이렇게 하지 않고, 한 번에 다 쌓아도 된다.
who %>%
gather(new_sp_m014:newrel_f65, key = "key", value = "cases", na.rm = TRUE) %>%
mutate(key = str_replace(key, "newrel", "new_rel")) %>%
separate(key, c("new", "type", "sexage"), sep = "_") %>%
select(-iso2, -iso3, -new) %>%
separate(sexage, c("sex", "age"), sep = 1)
## # A tibble: 76,046 x 6
## country year type sex age cases
## <chr> <int> <chr> <chr> <chr> <int>
## 1 Afghanistan 1997 sp m 014 0
## 2 Afghanistan 1998 sp m 014 30
## 3 Afghanistan 1999 sp m 014 8
## 4 Afghanistan 2000 sp m 014 52
## 5 Afghanistan 2001 sp m 014 129
## 6 Afghanistan 2002 sp m 014 90
## 7 Afghanistan 2003 sp m 014 127
## 8 Afghanistan 2004 sp m 014 139
## 9 Afghanistan 2005 sp m 014 151
## 10 Afghanistan 2006 sp m 014 193
## # ... with 76,036 more rows
12.6.1 Exercises
12.7 Non-tidy data
넘어가기 전에, non-tidy 데이터에 대해서 간략하게 얘기할 필요가 있다.
이 단원을 시작할 때, non-tidy data를 표현하기 위해서 경멸적으로 messy라고 표현했다.
사실 이건, 지나치게 단순화시킨 표현이다.
세상엔 유용하고 잘 만든 데이터 구조이지만 tidy data가 아닌게 많다.
다른 데이터 구조를 이용하는데에는 2가지 이유가 있다.
1. 다른 표현이 굉장히 좋은 퍼포먼스나 space 이득을 얻기 때문.
2. 분야에 있어서, 데이터를 저장하는 그들만의 관습이 tidy data의 관습과는 다르기 때문.
이러한 경우에 있어서는, tibble말고 다른게 필요할 수 있다.
그렇지 않고, natural한 관측치와 변수로 이루어진 rectangular 구조가 필요하다면,
tidy data가 너의 디폴트 선택이 되어야 할 것이다.
하지만 다른 구조를 쓰는 좋은 이유도 있다. tidy data만이 답은 아니다.
non-tidy data에 대해서 좀 더 알아보고 싶다면, 다음을 읽어볼 것.
http://simplystatistics.org/2016/02/17/non-tidy-data/