09 Wrangle Introduction
Data Wrangling에 대해서 배우게 될 것이다. 이건 갖고 있는 데이터를 visualisation과 modelling을 하는데 유용한 형식으로 바꾸는 예술 이건 매우 중요하다. 이게 없으면 당신의 데이터를 가지고 작업을 할 수 없다. Data wrangling은 3가지 주요 points로 이루어져 있다. 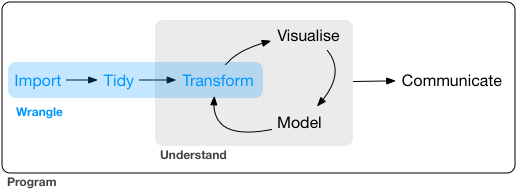 1. Import 2. Tidy 3. Transform
1. Import 2. Tidy 3. Transform
이 책은 다음과 같이 진행된다. - tibbles: 앞으로 계속 쓸, data frame의 변형인 tibble에 대해 배울 것이다. 기존의 data frames과 무엇이 다른지, 어떻게 만들 수 있는지에 대해 배울 것 - data import: 어떻게 디스크에 있는 데이터를 R로 읽어올건지. 일단 여기선 네모난 형식plain-text rectangular formats에 집중하는데, 다른 data 타입을 읽을 수 있는 pointers가 있는 패키지를 알려주겠다. - tidy data: transformation, visualisation, modelling을 하기에 편한, data를 저장하기 쉬운 일관적인 방법을 알려주겠다. 그 원리를 배우고, 어떻게 data를 tidy form으로 바꿀 수 있을지 배울 것
data wrangling은 이전에 조금 배웠던, data transformation도 포함하는 것. 여기서는 실전에서 자주 만나게 되는, 3가지 특정한 타입의 데이터들에 대한 스킬들에 집중한다.
- Relational data, 여러 개의 상호 관련된 데이터셋multiple interrelated datasets에 대해 처리할 수 있는 툴들을 준다.
- Strings, 문자열을 처리하는데 유용한 도구인, 정규표현식regular expression에 대한 소개
- Factors, R이 categorical data를 저장하는 것. 변수들이, 가능한 값들이 미리 정해져있고, 알려져 있을 때, 혹은 알파벳 순이 아닌 순서로 이용하기 원할 때(ex. Monday, Tuesday, ...)
- Dates and times, dates와 date-times에 쓸 핵심 툴들을 준다.