03 Data Visualisation
3.1 Introduction
"간단한 그래프가 다른 어떤 도구보다 데이터 애널리스트에게 많은 정보를 전달해준다." - 존 튜키
“The simple graph has brought more information to the data analyst’s mind than any other device.” — John Tukey
이 chapter에서는 ggplot2를 이용해, 데이터를 어떻게 visualise할지 알려준다.
R에는 그래프를 만들어주는 몇 가지 시스템들이 있지만, ggplot2는 가장 우아하고 다재다능하다.
ggplot2는 그래픽의 문법을 구현implement했다.
그래프를 만들고 묘사하는데 있어, 일관적인 시스템을 정립했음.
ggplot2와 함께라면, 하나의 시스템만을 배워서 더 빠르게, 그리고 많은 곳에 응용할 수 있다.
시작하기 전에, ggplot2의 이론적인 근거들을 더 배우고 싶다면,
The Layered Grammar of Graphics 이걸 읽기를 추천한다.
3.1.1 Prerequisites
이 chapter에서는, tidyverse의 핵심 멤버 중 하나인, ggplot2에 집중할 것이다.
데이터셋을 접근하고, 필요한 함수를 사용하기 위해서, tidyverse를 로드하자.
library(tidyverse)
이 코드 한줄로 핵심 tidyverse를 로드할 수 있다.
거의 모든 데이터 분석에서 사용할 패키지들이다. (실제로 없으면 안 되는 수준이다.)
base R 혹은 로드한 다른 패키지들의 함수와, 이름이 같아서 충돌하는지도 알려준다.
만약에 이 코드를 실행했는데, "there is no package called 'tidyverse'"라는 에러 메시지가 나오면,
먼저 설치를 해야한다. 그리고 나서 library()를 다시 실행해야 한다.
install.packages("tidyverse")
library(tidyverse)
패키지 설치는 처음 한 번만 하면 되는데, 패키지를 로드 하는 것은 세션을 시작할때마다 해줘야 한다.
(독자가 beginner라고 가정하고 설명을 해놓은듯..)
어떤 함수가 어디에서 왔는지를 명시해주고 싶다면, package::function()이라는 특별한 형식으로 사용해줘야 한다.
예를 들어, ggplot2::ggplot()라고 하면,
우리가 ggplot2라는 패키지에서 ggplot()이라는 함수를 사용하고 있다는 걸 뜻한다.
3.2 First steps
다음의 질문을 대답하는데 있어, 첫 번째 그래프를 사용해 볼 것이다.
큰 엔진을 사용하는 차들이, 작은 엔진을 사용하는 차들보다 기름을 많이 먹을까?
Do cars with big engines use more fuel than cars with small engines?
이미 답을 알고 있을수도 있지만, 더 정확하게 답을 알아보자.
엔진 사이즈와 연비(fuel efficiency)는 어떤 관계가 있을까? 양의 관계? 음의 관계? 선형? 비선형?
3.2.1 The mpg data frame
ggplot2 패키지에 있는 mpg라는 데이터 프레임을 이용해서 답을 찾을 수 있다.
데이터 프레임은, 변수들variables을 열(column)에, 관측치들observations을 행(row)에 저장해놓은 네모난 컬렉션.
mpg는 US Environmental Protection Agency가 모은 38개 모델의 차들에 대해 관측치들을 가지고 있다.
mpg
## # A tibble: 234 x 11
## manufacturer model displ year cyl trans drv cty hwy fl class
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
## 1 audi a4 1.8 1999 4 auto~ f 18 29 p comp~
## 2 audi a4 1.8 1999 4 manu~ f 21 29 p comp~
## 3 audi a4 2 2008 4 manu~ f 20 31 p comp~
## 4 audi a4 2 2008 4 auto~ f 21 30 p comp~
## 5 audi a4 2.8 1999 6 auto~ f 16 26 p comp~
## 6 audi a4 2.8 1999 6 manu~ f 18 26 p comp~
## 7 audi a4 3.1 2008 6 auto~ f 18 27 p comp~
## 8 audi a4 q~ 1.8 1999 4 manu~ 4 18 26 p comp~
## 9 audi a4 q~ 1.8 1999 4 auto~ 4 16 25 p comp~
## 10 audi a4 q~ 2 2008 4 manu~ 4 20 28 p comp~
## # ... with 224 more rows
mpg에 있는 변수들 중 몇 가지만 설명해보면:
-
displ는 차의 엔진 사이즈다. 리터로. -
hwy는 고속도로 위에서 차의 연비. miles per gallon으로 mpg.
이 값이 낮으면 연비가 더 안 좋다는거지 뭐.
mpg에 대해서 더 배우고 싶다면, ?mpg를 통해서 help page를 봐라.
3.2.2 Creating a ggplot
mpg를 그려보기 위해서는, displ을 x축에 놓고, hwy를 y축으로 놓는 다음의 코드를 실행해보자.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy))
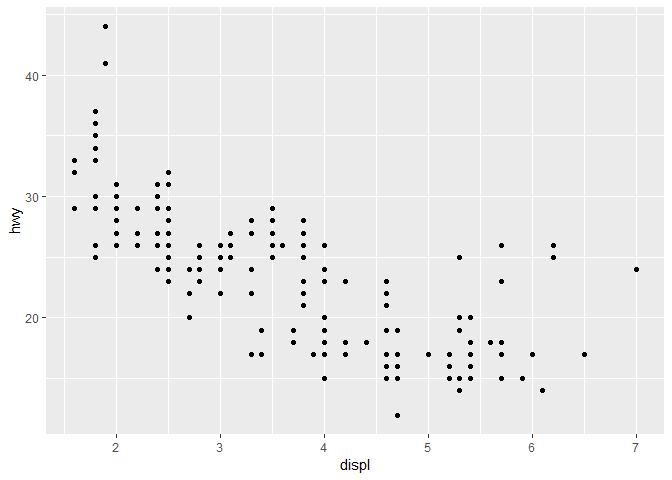
이 그래프는, 엔진 사이즈(displ)와 연비(hwy)간에 음의 관계가 있다는 것을 보여준다.
다른 말로 하면, 엔진이 큰 차는 기름을 더 먹는다는 것이다.
그럼 이게, 엔진 사이즈와 연비간의 관계에 대한 우리의 가설을 지지하는가 아님 반대하는가?
ggplot2을 사용할 때면, ggplot()이라는 함수와 함께 그래프를 그리기 시작하는 것이다.
ggplot()는 레이어들layers을 쌓아갈 수 있는 coordinate system을 만들어준다.
ggplot()의 첫 번째 인자argument는, 그래프를 그릴 때 사용할 데이터셋이다.
그래서 ggplot(data = mpg)는 텅 빈 그래프를 만들어준다. 여기서는 보여지는게 아무것도 없다.
ggplot()에 레이어를 하나씩 하나씩 더해가면서 원하는 그래프를 완성하는 것이다.
geom_point()라는 함수는 그래프에다 포인트를 더해준다. 그래서 scatterplot을 만들어주는 것.
geom_으로 시작하는 엄청 많은 함수들이 있고, 이 chapter를 배워나가면서 배워나가게 될 것이다.
ggplot2의 각 geom 함수들은 mapping argument를 받는다.
이 argument가 데이터셋에 있는 변수들을 어떻게 시각적visual으로 map해줄지를 정해준다.
mapping argument는 항상 aes()라는 것과 짝을 이룬다.
aes()안에는 x와 y argument들이 어떤 변수를 x축과 y축으로 map할건지를 정해준다.
3.2.3 A graphing template
이 코드를, ggplot2을 이용해서 그래프를 만들 수 있는, 재사용한 템플릿resuable template으로 만들어보자.
아래에 보이는 코드에서, <>로 감싸진 부분은, 원하는 것으로 대체할 수 있다.
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(mapping = aes(<MAPPINGS>))
남은 chapter에서는, 다른 타입들의 그래프를 만드는데 있어,
이 템플릿을 어떻게 완성하고 확장시킬것인지를 보여줄 것이다.
<MAPPINGS> 부분부터 시작해보자.
3.2.4 Exercises
3.3 Aesthetic mappings
"그림의 가장 중요한 가치는, 우리가 기대하지도 않았던 것을 알아차리게 한다는 점이다." - 존 튜키
밑의 그래프를 보면, 한 그룹의 포인트들이(빨간색으로 표시된) 선형적 추세에서 떨어져 있는 것을 볼 수 있다.
이 차들은 우리가 예상했던 것보다 더 좋은 연비를 가지고 있다.
이 차들이 왜 그런지를 설명할 수 있을까? 
이 차들이 하이브리드라고 가정해보자.
이 가정을 테스트해볼 한 가지 방법은, 각 차들의 class를 확인해보는 것이다.
mpg 데이터셋의 class 변수는, 차들을 compact, midsize, SUV로 분류해준다.
만약에 저 outlying 포인트들이 하이브리드라면, compact cars나 subcompact cars로 분류가 되어야한다.
(이 데이터는 하이브리드 트럭이나 SUV가 popular해지기 전에 모아졌다는 것을 인지해두자.)
이제 여기서, class라는 세 번째 변수를, aesthetic으로 mapping해서, 2차원의 scatterplot에 추가할 수 있다.
aesthetic은, 그래프에서 오브젝트가 어떻게 표현이 될지 시각적 특징visual property이다.
aesthetics는 사이즈, 모양shape, 색을 포함한다.
aesthetic 특성들 값을 변화시키면서, 아래와 같이 포인트들의 모양을 바꿀 수 있다.
데이터를 묘사하기 위해 "값value"이라는 단어를 사용했으니깐,
aesthetic 특성들 값을 지칭하기 위해서는 "레벨level"이라는 단어를 사용하겠다.
아래에서, 포인트의 사이즈를 바꾸기도, 모양을 바꾸기도, 색을 바꾸기도 해보았다.
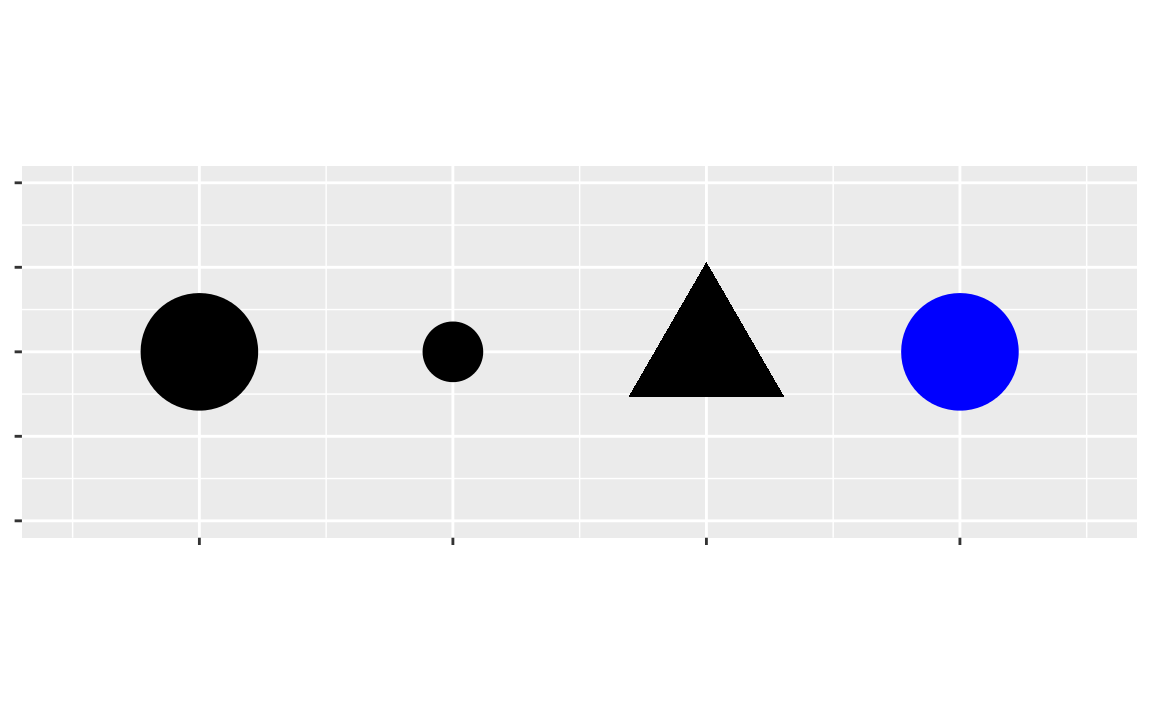
데이터셋의 변수들을 aesthetics로 mapping해서, 데이터에 대한 정보를 전달할 수 있다.
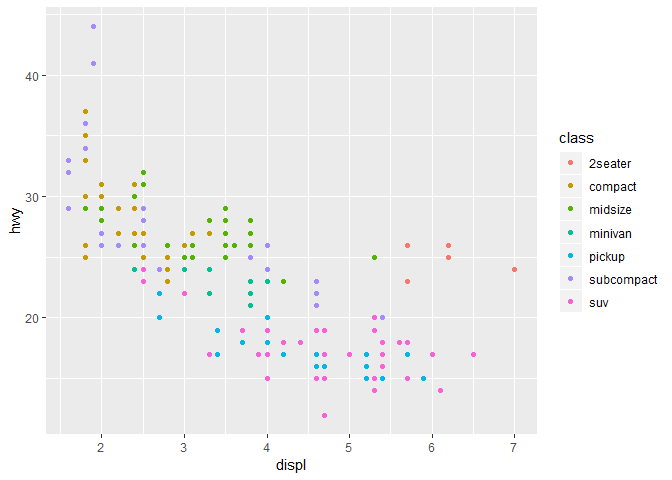
예를 들어, class 변수에, 색을 map해서 각 차들이 어떠한 클래스인지를 보이게 할 수도 있다.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = class))
 (Hadley와 같이 영국식 영어를 더 좋아한다면,
(Hadley와 같이 영국식 영어를 더 좋아한다면, color 대신에 colour를 사용해도 된다.)
변수에 aesthetic을 map하기 위해서는, 위에서 했던 것같이,
aes()안에서 변수의 이름과 aesthetic의 이름을 연관시켜라. ggplot2는 자동적으로 '변수의 unique한 값들'에다가 'aesthetic의 unique한 레벨들'을 할당할 것이다.
이 과정process은 scaling이라고 알려져있다.
ggplot2는 또한 그래프 옆에, 어떤 레벨이 어떤 값과 연관되어 있는지, legend도 추가해준다.
자, 그럼 위에서 봤던 그 outlying points는 무엇이었냐?
색깔을 보면 알 수 있듯이, two-seater 차들이었다.
이 차들은 하이브리드가 아니고, 스포츠카였다!
스포츠카들은 SUV나 픽업 트럭과 같은 큰 엔진을 가지고 있지만,
midsize나 compact 차들과 같은 작은 자체를 가지고 있어서, 연비가 좋았던 것이다.
지나고나서보니깐in hindsight, 이러한 차들은 큰 엔진을 갖고 있기 때문에 하이브리드 차가 아니다.
위의 예를 보면, class 변수를 color aesthetic에다가 map을 했는데,
비슷한 방법으로 size aesthetic에다가 map을 할 수도 있다.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, size = class))
## Warning: Using size for a discrete variable is not advised.
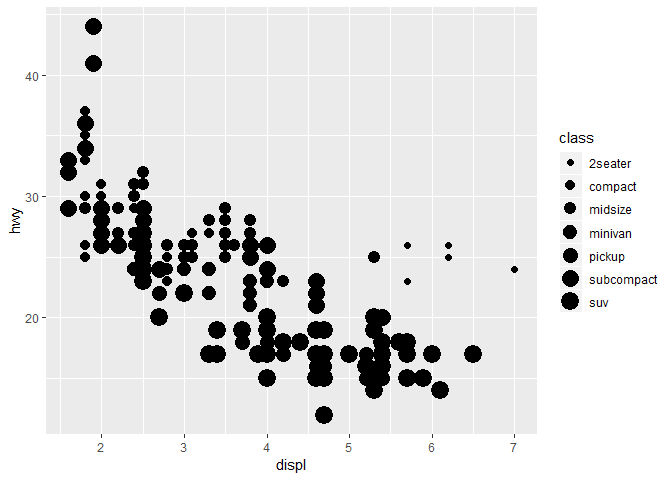 그래프를 보면 알겠지만, 구별이 잘 안된다. warning도 뜬다.
그래프를 보면 알겠지만, 구별이 잘 안된다. warning도 뜬다.
이렇게 순서가 없는 변수unordered variable을 ordered aesthetic로 mapping하는 것은 좋은 방법이 아니다.
class라는 unordered variable을, size라는 ordered aesthetic으로 mapping하는 건 좋은 생각이 아니라고.
이런 식으로 class 변수를 alpha aesthetic(투명성transparency 조절), shape aesthetic으로 전달할 수 있다.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, alpha = class))
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, shape = class))
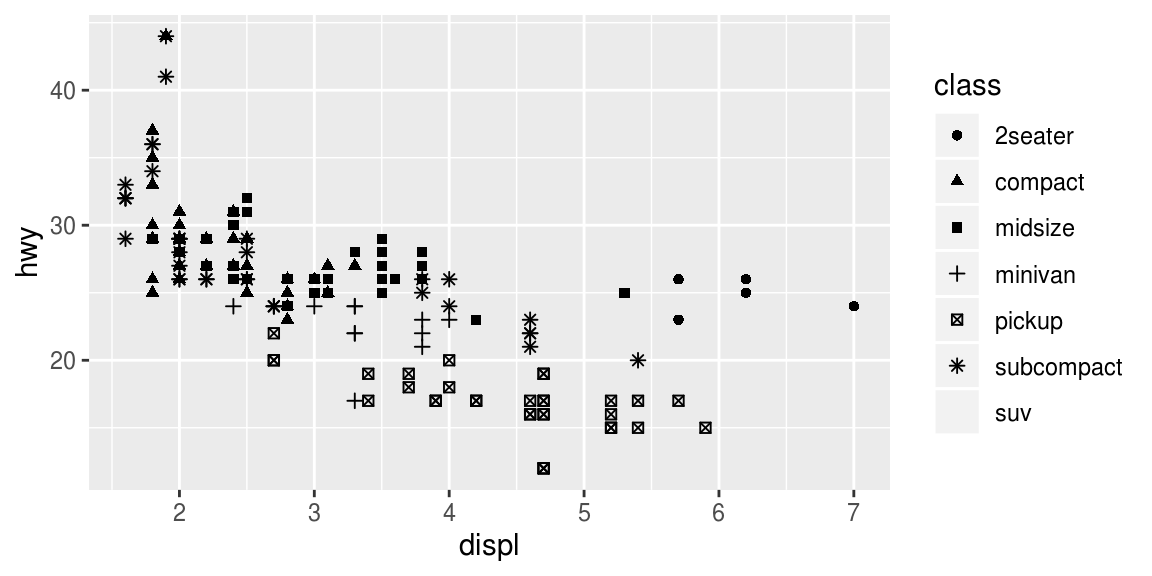
그런데, shape aesthetic을 사용한 그래프에서, SUV들은 어디로 간거지?
ggplot2는 한 번에 여섯 개의 shapes까지만 사용할 수 있다.
그래서 디폴트로, 이 숫자 이상의 그룹들은 그려지지 않는다.
각 aesthetic에 대해, aes()를 사용해서 변수와 aesthetic의 이름들을 연결시킬 수 있다.
aes() 함수는, 레이어에서 사용되는 각 aesthetic mapping 모아서, layer의 mapping argument로 전달한다.
이것의 문법syntax는 x, y에 무엇이 위치하게 되고, 변수를 map하는데 어떠한 시각적 특징을 이용했는지 강조한다.
aesthetic을 map하게 되면, ggplot2가 나머지를 알아서해준다.
합리적인 scale을 정해주고, 레벨들과 값을 설명해주는 legend도 만들어준다.
x, y 축에 뭐가 있는지에 대해서는 legend를 만들지는 않지만, 라벨을 만들어준다.
axis 선은, location과 값을 mapping한 것을 설명한다는 점에서, legend와 같이 행동한다.
당연히, geom의 aesthetic 특성들을 매뉴얼하게 설정할 수도 있다.
예를 들어, 모든 점들을 파란색으로 만들 수도 있다.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy), color = "blue")
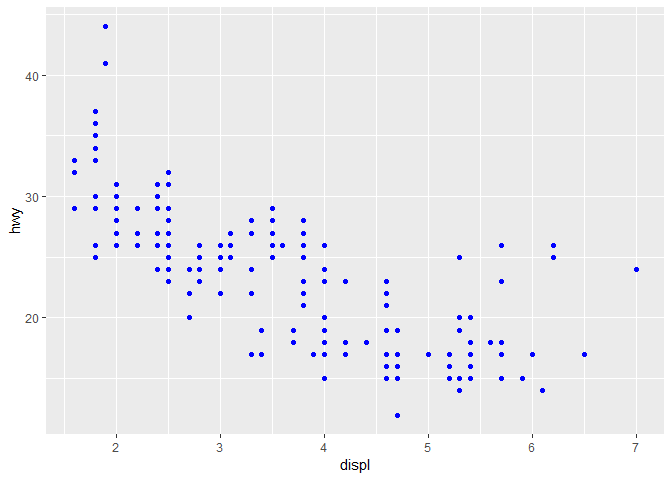
여기서, 색은 변수에 대한 어떠한 정보도 전달해주지 못하고, 그냥 외형만 바꿔준다.
aesthetic을 매뉴얼하게 정하기 위해서는, 위의 코드처럼 aes() 밖에다가 두어야한다.
그 aesthetic이 말이 되게끔 레벨level을 정해주어야 한다.
- 색은 'character string'으로.
- 사이즈는 mm으로.
- 모양shape은 다음 그림에 나와있는 숫자로.
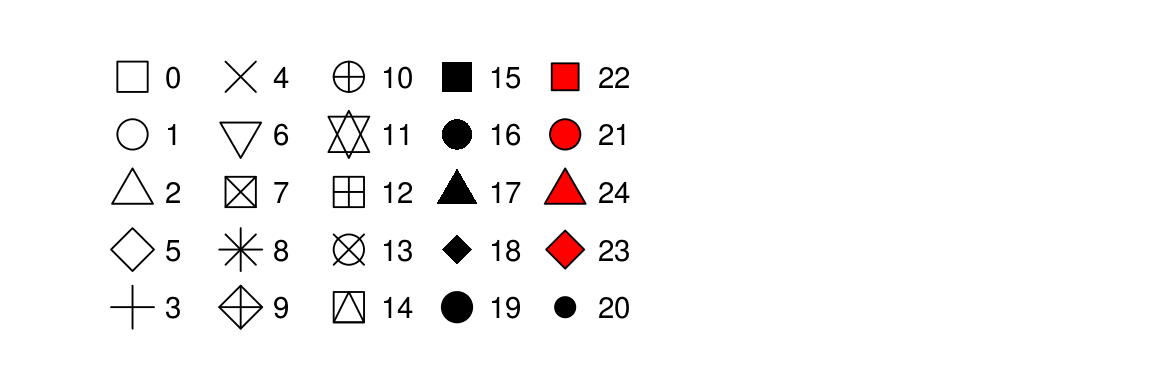
이 25개의 shape들은 숫자로 구분되어 있다.
몇몇 중복들duplicates이 있는 것으로 보인다. 예를 들어, 0, 15, 22는 전부 네모다.
차이점은, colour와 fill aesthetic들이랑 상호작용할 수 있는지에 있다.
텅 빈 shape들, (0 - 14)는 경계선이 colour로 결정될 수 있다.
solid한 shape들, (15 - 18)은 colour로 색을 채울fill 수 있다.
색이 찬 shape들, (21 - 24)는 경계선을 colour로, 색을 fill로 채울 수 있다.
3.3.1 Exercises
3.4 Common problems
R 코드를 치다보면, 많은 문제들을 만나게 될 것이다.
걱정마라. 누구나 그러니깐.
나는(Hadley는) R 코드를 수 년간 쳐왔지만, 오늘도 작동 안 되는 코드를 친다.
당신이 타이핑한 코드와 여기에 써져있는 코드를 신중하게 비교해보는 것으로 시작해보자.
R은 극도로 까다로워서, 캐릭터character하나 잘못 쓰면 모든게 바뀔 수 있다.
모든 (는 )와 짝지어질 수 있도록 하고, 모든 "는 다른 "와 짝지어질 수 있도록 하자.
가끔 아무것도 일어나지 않는 코드를 실행할 수도 있는데, 콘솔의 왼쪽을 살펴보자.
만약 + 가 있다면, R은 타이핑이 안 끝났고 더 쓸게 있나보다 생각하는 것이다.
이럴 경우에는 그냥 Esc 키를 눌러서 현재 커맨드를 버리고, 처음부터 다시 치는게 더 쉽다.
ggplot2 그래픽스를 사용할 때 저지르는 흔한 문제 중 하나는 +를 잘못된 자리에 놓는 것.
+는 줄 끝에 와야지, 시작에 오면 안 된다.
다시 말해, 다음과 같이 치지 않도록 조심하자.
ggplot(data = mpg)
+ geom_point(mapping = aes(x = displ, y = hwy))
여전히 어떤 문제가 있다면, help를 해봐라.
어떠한 R 함수에 대해서도, ?함수_이름을 콘솔에 치거나,
RStudio에서는 함수 이름을 드래그한다음 F1 키를 누르면 된다.
이 documentation이 별로 쓸모 없어 보여도 괜찮다.
맨 밑의 examples으로 내려가서 필요한 함수를 보면 된다.
만약 이것도 별 도움이 되지 않는다면, 에러 메세지를 신중하게 읽어봐라.
가끔은 답이 거기에 숨어있을 것이다. 하지만 R 초보라면 이해가 안 될수도 있고..
다른 좋은 방법은 구글링하는 것.
에러 메세지를 구글링하면, 누가 이미 같은 질문을 하고 답을 해놨을 수도 있다. ___ ## 3.5 Facets 추가적인 변수들을 추가하는 방법은, aesthetics를 이용하는 것.
add additional variables. 이게 이 때까지 했던 것이고,
다른 방법으로(aes를 이용하지 않고)는, 특히나 범주형categorical 변수들에 유용한 방법으로는,
너의 plot을 facets로 쪼개보는 것이다.
데이터의 각 부분집합subset에 맞는 그래프를 그리는 것.
하나의 변수에 따라 그래프를 facet하고싶다면, facet_wrap()을 사용하자.
facet_wrap()의 첫 번째 인자argument는 공식formula이어야 한다.
~변수 이렇게 나오는 공식.
(여기서 말하는 formula는 R에서 데이터 구조의 이름이다. 수학 공식의 equation이 아니고.)
facet_wrap()에 전달하는 변수는 이산형이어야 할 것이다.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class, nrow = 2)
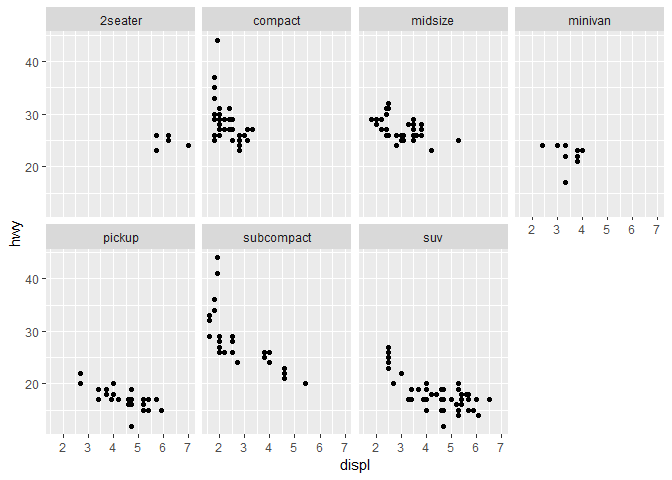
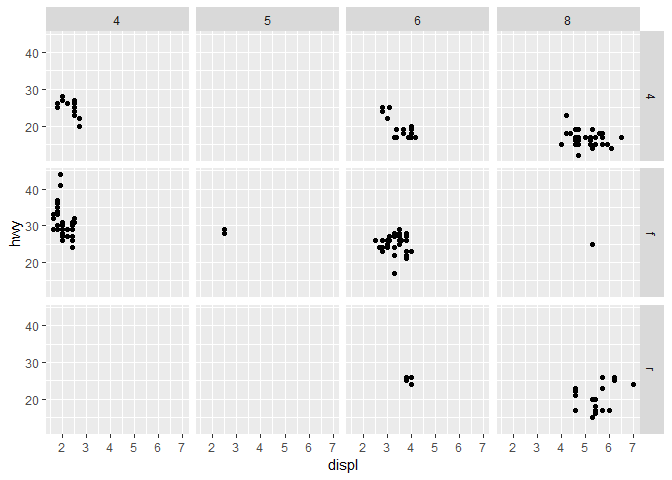
"2개의 변수들 조합"에 대한 그래프를 facet하고 싶다면, facet_grid()를 사용하면 된다.
facet_grid()의 첫 번째 인자argument도 formula다.
여기 공식에서 두 변수들은, ~로 분리되어 있어야한다.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(drv ~ cyl)
facet을 하는데 있어 row나 column 차원을 쓰기가 싫다면, 변수 이름 대신에 .을 사용해도 된다.
예를 들어서,
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ cyl)
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(. ~cyl)
각각을 직접 해보자.
3.5.1 Exercises
3.6 Geometric objects
다음의 두 그래프들은 얼마나 비슷한가?
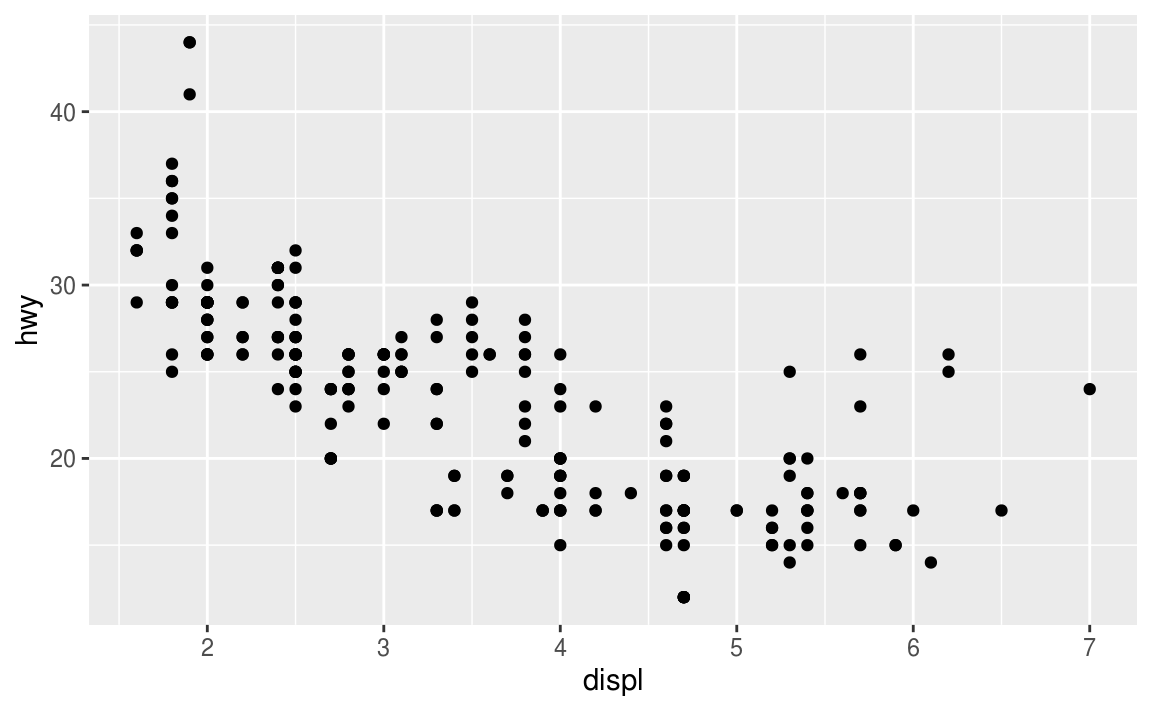
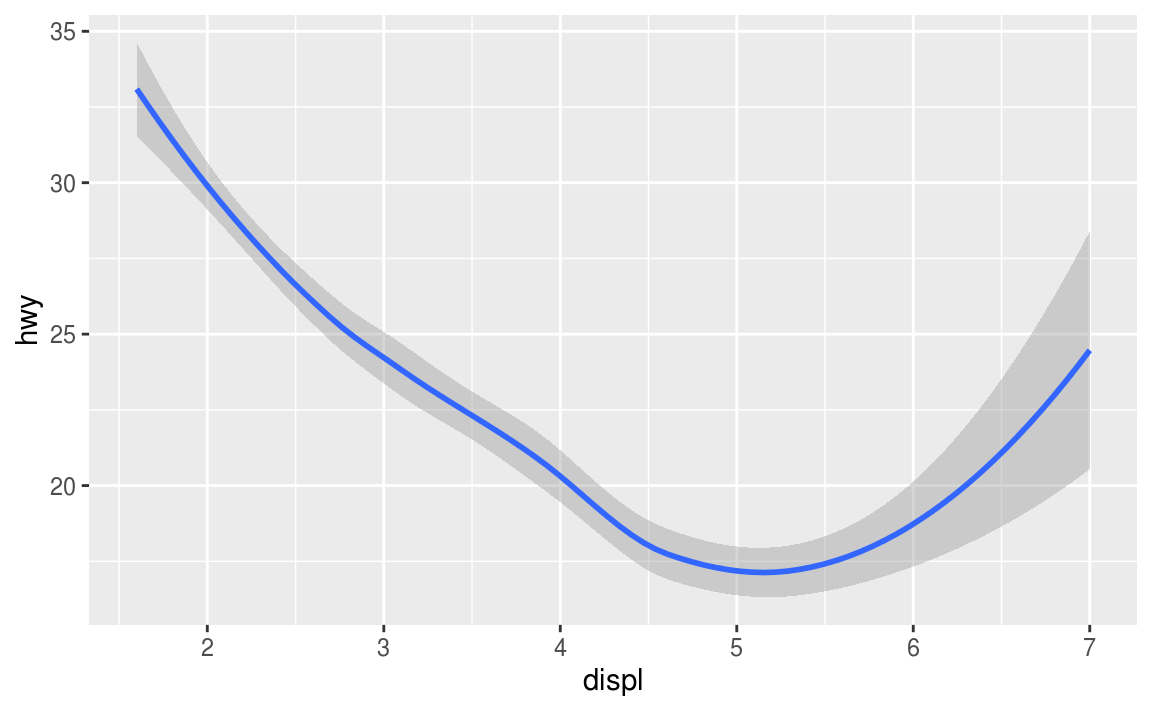
두 그래프들 모두 같은 x, y 변수들을 갖고 있고, 같은 데이터를 묘사describe하고 있다. 하지만 이 두 그래프들은 동일한 것은 아니다. 각 그래프는 데이터를 표현하는데 있어 다른 시각적 오브젝트를 사용했다. ggplot2의 용어로 말하면, 각각은 다른 geoms를 사용하고 있다.
geom은 데이터를 표현하기 위해 그래프가 사용하는 기하학적geometrical인 오브젝트다. 사람들은 가끔 그래프를, 어떤 geom을 이용했는지를 바탕으로 표현하기도 한다. 예를 들어서, 막대 그래프bar chart는 bar geom을 이용하고, 선형 차트line chart는 line geom을 이용하고, 박스 플랏box plot은 boxplot geom을 이용하고, 이런 식으로. 산점도scatterplot는 예외다. 얘네는 point geom을 이용한다.
위에서 볼 수 있듯이, 그래프의 geom을 바꾸고 싶다면 다른 geom 함수를 사용하면 된다. 왼쪽은 point geom을 사용했고, 오른쪽은 smooth geom을 사용한 것. 그리고 오른쪽이 데이터에 좀 더 잘 어울린다fit.
그래프의 geom을 바꾸는데 있어, 해야할 것이라곤, ggplot() 다음에 추가할 geom 함수만 바꿔주는 것. 예를 들어서, 위의 그래프들을 만드는데 있어, 다음의 코드들을 사용하면 된다.
# 왼쪽
ggplot(data = mpt) +
geom_point(mapping = aes(x = displ, y = hwy))
# 오른쪽
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy))
ggplot2의 모든 geom 함수들은, mapping 인자argument를 받는다. 하지만, 모든 aesthetic이 모든 geom들과 작동하는 건 아니다. 그러니깐 예를 들어서, point의 shape은 정해줄 수 있어도, line의 shape은 정해줄 수 없다. 대신에, line의 경우에는 linetype을 정해줄 수 있겠지.
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy, linetype = drv))
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
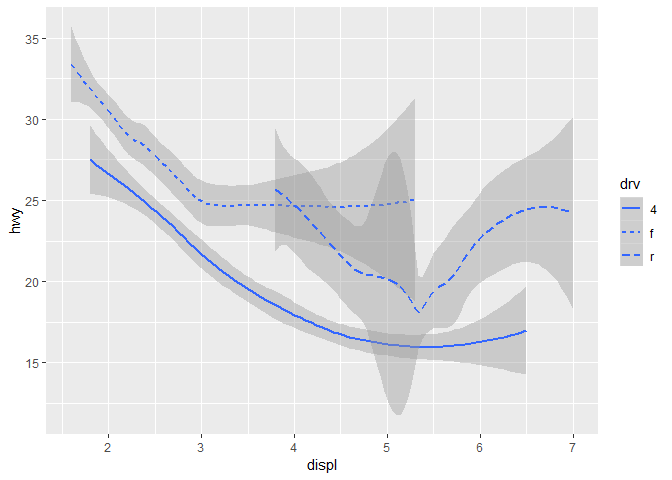
여기서 geom_smooth()는, drv 값에 따라 차들을 나눠서, 3개의 분리된 라인들로 표시. 이게 차의 drivetrain을 묘사한거라는데, 이게 뭔지는 모르겠다.
하나의 선은 4라는 값을 갖고 있는 모든 점들을 묘사해놨고, 다른 선은 f라는 값에 따라, 또 다른 선은 r이라는 값에 따라. 4는 4륜구동, f는 앞바퀴구동, r은 후륜구동. drivetrain이 이거구나.
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
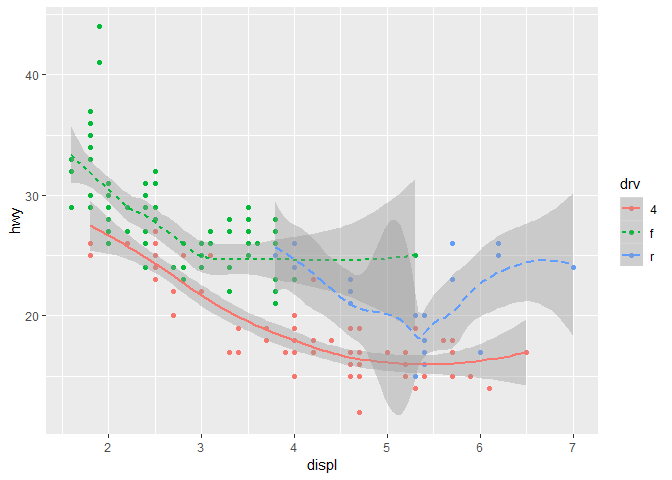
위의 그래프를 보면, 두 개의 geoms가 하나의 그래프에 들어가있는 걸 볼 수 있다. 이제 하나의 그래프에, 여러 개의 geoms를 두는 것에 대해 배워볼거다.
ggplot2는 30개가 넘는 geoms를 제공한다. 그리고 확장팩은 더 많은걸 제공한다. (https://www.ggplot2-ets.org에 예들이 나와있다.) 포괄적인 개요overview를 볼 수 있는 가장 좋은 방법은, R cheatseet을 보는 것. http://rstudio.com/cheatsheets 하나의 geom에 대해 더 배워보고 싶다면, help를 사용해라. ?geom_smooth 이런 식으로.
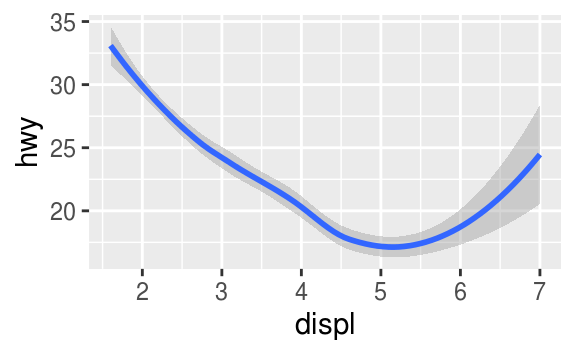
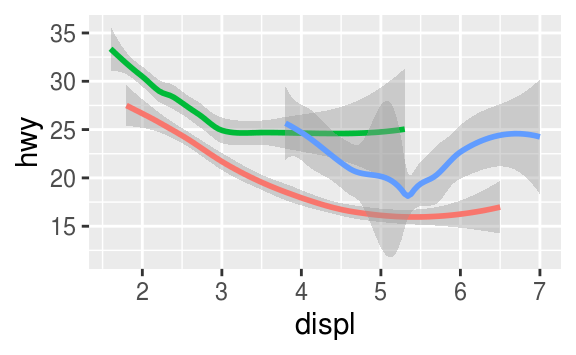
geom_smooth()와 같은 많은 geom들이, 여러 행들의 데이터를 표현하는데 있어, 하나의 기하학적 오브젝트를 사용한다. 이러한 geom들에 대해서, 범주형 변수들에다가 group aesthetic을 설정해줄 수 있다. 이러고나면 ggplot2가, grouping 변수의 unique한 값들마다, 별개의 오브젝트들을 그려줄 것이다. ggplot2 will draw a separate object for each unique value of the grouping variable. group aesthetic은 자동으로 legend를 만들거나 특이한 짓distinguishing features을 하지 않기 때문에, 이 기능에 의지하는 것도 나쁘지 않다.
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy))
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy, group = drv))
ggplot(data = mpg) +
geom_smooth(
mapping = aes(x = displ, y = hwy, color = drv),
show.legend = FALSE
)

하나의 그래프에다가 여러 개의 geoms를 표시display하려면, ggplot()에다가 여러 개의 geom 함수들을 추가하면 된다.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
geom_smooth(mapping = aes(x = displ, y = hwy))
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
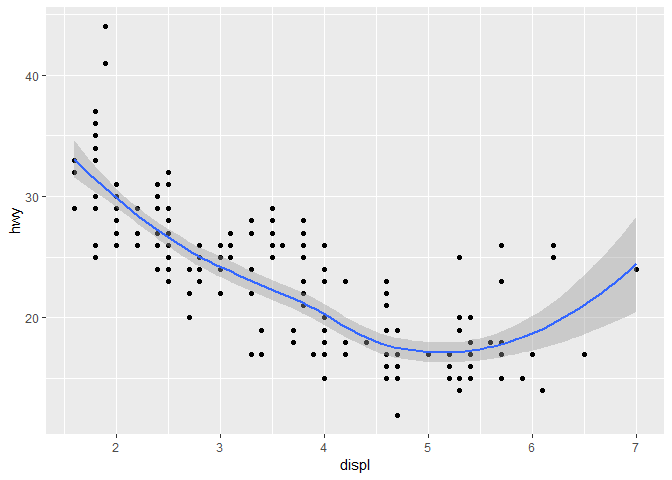
하지만 이렇게 쓰면 mapping = aes(x = displ, y = hwy)) 이 부분이 중복되었다는게 문제다. 만약, y 축을 hwy가 아닌 cty로 바꾸려고 한다면? 2번 고쳐야됨. 그래서, geom_point() 안에 것은 수정해도 geom_smooth() 안에 것은 깜빡할 수가 있음.
이런 중복 문제를, ggplot()안의 mapping으로 넘겨줌으로써 해결할 수 있다. 위의 코드를 아래와 같이 다시 써볼 수 있다는 말.
ggplot()안의 매핑으로 넣어주면 global, geom_*()안으로 넣어주면 local.
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth()
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
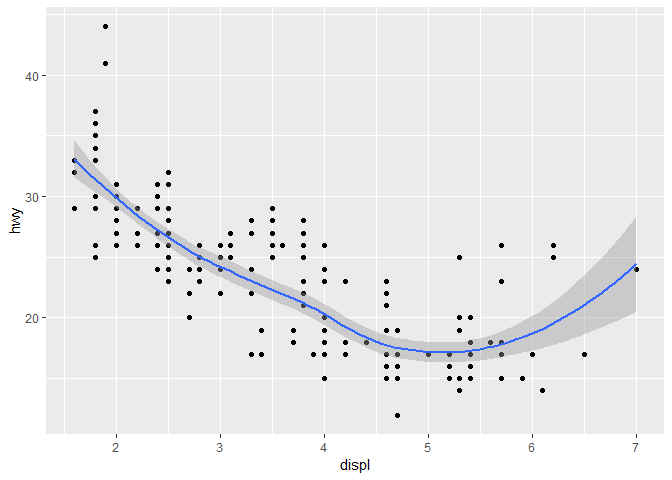
geom 함수 안에다가 mapping을 넣어놓으면, ggplot2는 로컬 매핑mapping으로 다룬다. 그래서 서로 다른 레이어들이 서로 다른 aesthetics를 갖도록 할 수도 있다.
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
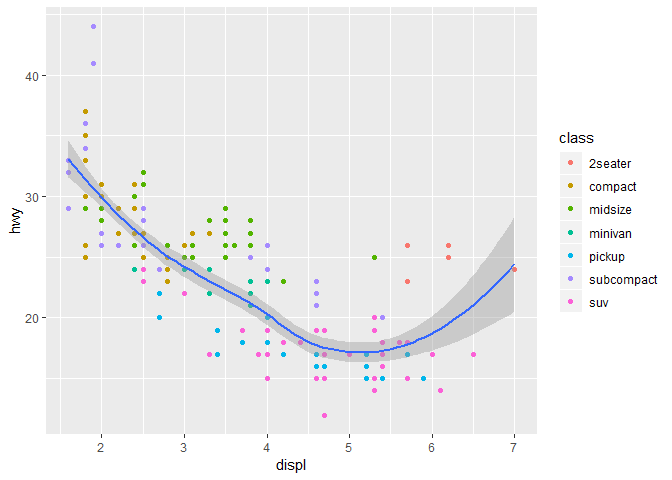
geom_point(mapping = aes(color = class)) +
geom_smooth()
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
각 레이어마다 다른 data를 사용하는 것도 가능하다. 산점도scatterplot의 경우엔 mpg 데이터셋 전체에 대해, smooth line의 경우엔 mpg 데이터셋의 부분집합에 대해, 그리는 것도 가능하다. geom_smooth()에만 데이터 인자argument를 바꾸면, ggplot()에 원래 있던 global 데이터 인자를 덮어씌운다.
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point(mapping = aes(color = class)) +
geom_smooth(data = filter(mpg, class == "subcompact"), se = FALSE)
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
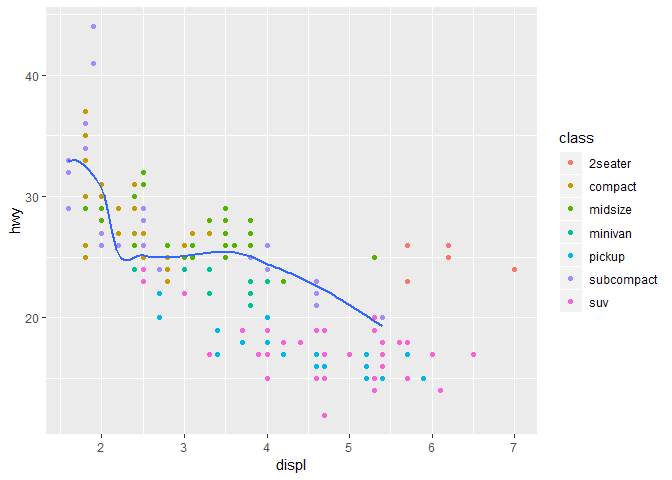
filter()를 어떻게 쓰는지는 data transformations에서 배울 것이다. 여기서는 그냥 subcompact 차들을 선택했다는 것만 이해하자.
3.6.1 Exercises
3.7 Statistical transformations
이제, 막대 그래프bar chart를 봐보자. 막대 그래프는 단순해보이지만, 흥미롭다. 왜냐하면 그래프에 대한 사소한 것들을 알려주기 때문. geom_bar()로 그린, 기초적인 막대 그래프를 생각해보자. 다음의 그래프는, cut을 기준으로 그룹해서, diamonds 데이터셋에 있는 다이아몬드의 총 수를 나타낸다. diamonds 데이터셋은 ggplot2에 있는 것으로, 약 54000개 다이아몬드의 정보를 가지고 있다. 각 다이아몬드의 price, carat, color, clarity, cut이라는 정보들.
막대 그래프를 보면 알 수 있듯, 높은 퀄리티의 다이아몬드들이, 낮은 퀄리티의 다이아몬드들보다 많다.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut))
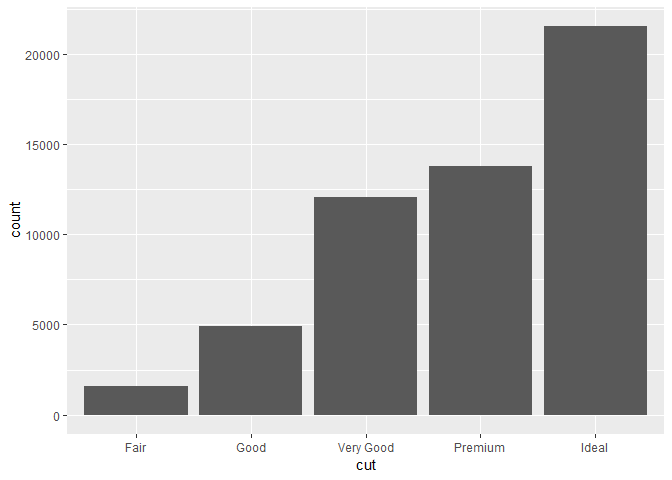
x축에는, cut이라는 변수가 있다. 그런데 y축에는, 카운트count를 나타나는데, 얘는 diamonds에 있는 변수가 아니다! 그럼 이 count라는 값은 어디서 나온건지?
아까 그려봤던 산점도 같은 많은 그래프들이, 데이터셋에 있는 그대로의 값들을 그린다. 그런데 막대 그래프bar chart는, 그래프에 추가할 새로운 값들을 계산한다. 이런 것들이 있는데, 얘네들은 그래프에 추가할 새로운 값을 계산한다.
-
막대 그래프, 히스토그램, 그리고 빈도 다각형frequency polygons은 데이터를 구간화bin하고, 구간에 해당하는 포인트 수를 각 구간에 표시.
-
선을 부드럽게 그어주는 애들smoothers은 데이터에 맞는 모형을 적합fit해준다음, 모형의 predictions를 그린다.
-
박스플랏은 분포의 요약summary 통계량을 계산하고, 이걸 특별하게 포맷된 박스에다가 표시한다.
이렇게 그래프에 필요한 새로운 값들을 계산해주는 알고리즘을 stat이라고 부른다. statistical transformation의 줄임말로써. 아래의 그림은 geom_bar()의 경우엔 이 프로세스가 어떻게 작동하는지를 보여준다.
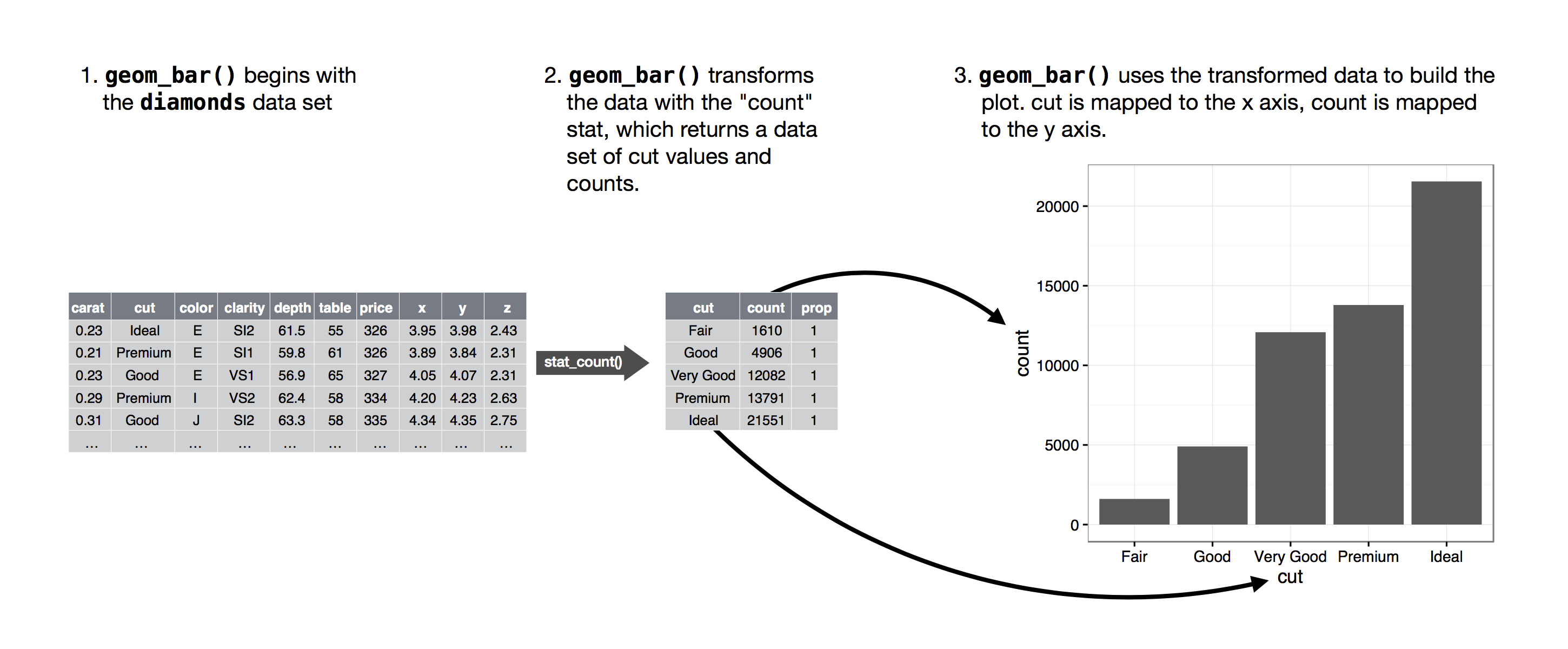
stat 인자argument의 기본 값을 조사해봄으로써, geom이 어떠한 stat을 사용하는지를 알 수 있다. 예를 들어, ?geom_bar하면 stat의 기본 값이 "count"라는걸 알 수 있다. geom_bar()이 stat_count()를 사용하고 있다는 것. stat_count()는 geom_bar()과 같은 페이지에 다큐먼트가 있다. 그리고 이걸 밑으로 내리면, "Computed variables"라는 섹션이 있는걸 볼 수 있다. count와 prop라는 2개의 새로운 변수들을 어떻게 계산하는지를 보여준다.
geoms와 stats를 섞어서 쓸 수 있다. 예를 들어, 이전에 그래프를 geom_bar() 대신 stat_count()를 이용해서 만들수도 있다.
ggplot(data = diamonds) +
stat_count(mapping = aes(x = cut))
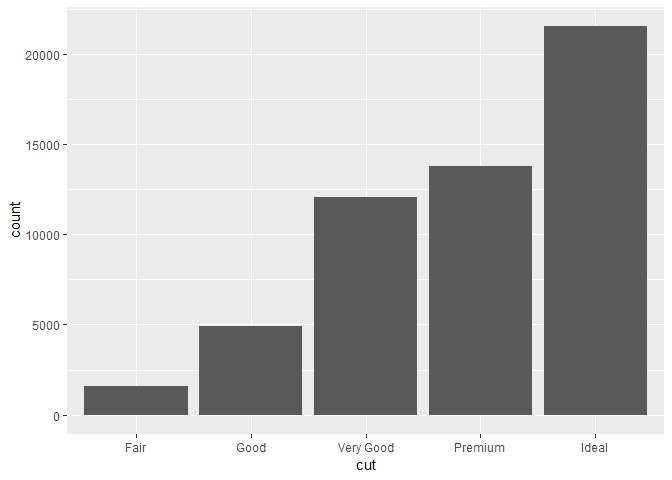
이게 가능한 이유는, 모든 geom은 디폴트 stat이 있고, 모든 stat은 디폴트 geom이 있기 때문. 이 말인즉슨, underlying statistical transformation에 대해 걱정하지 않고, geom을 이용하면 된다는 것. 그런데 이게 가끔 explicit하게 필요한 3가지 이유가 있다.
- 디폴트 stat을 덮어씌우고 싶을 때. 아래의 코드에서,
geom_bar()의 stat을, 디폴트인 count에서 identity로 바꿨다. 이러고 나면 데이터 y 변수의 값들을, 그래프의 높이로 그려준다. 불행하게도, 사람들이 보통 막대 그래프라고 하면, 이걸 생각하고 있는 것이다. 그래프의 높이가 될 값이, 데이터에 이미 존재한다고 생각하는 것.
demo <- tribble(
~cut, ~freq,
"Fair", 1610,
"Good", 4906,
"Very Good", 12082,
"Premium", 13791,
"Ideal", 21551
)
ggplot(data = demo) +
geom_bar(mapping = aes(x = cut, y = freq), stat = "identity")
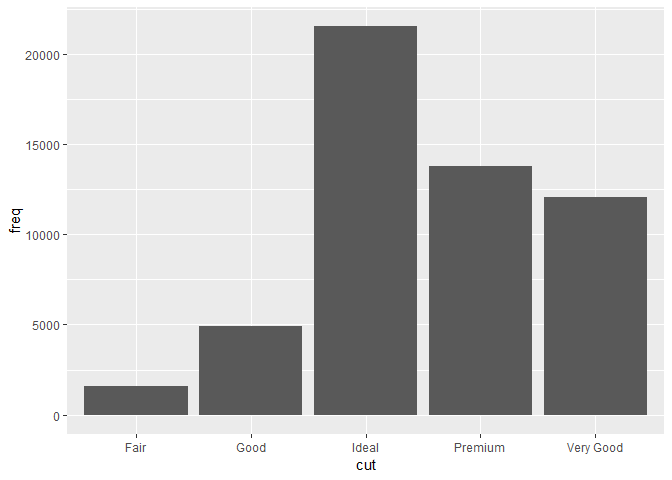
<- 나 tribble()이 뭔지 모른다고 걱정하지말자. 뭐 이미 문맥상 이해했을 수도 있는데, 곧 배우게 될 거다!
- 디폴트 매핑을, 변형된 변수가 아닌 다른 aesthetics로 바꾸길 원할 수 있다. 예를 들어, 막대 그래프가 count가 아닌 proportion을 나타내도록.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, y = ..prop.., group = 1))
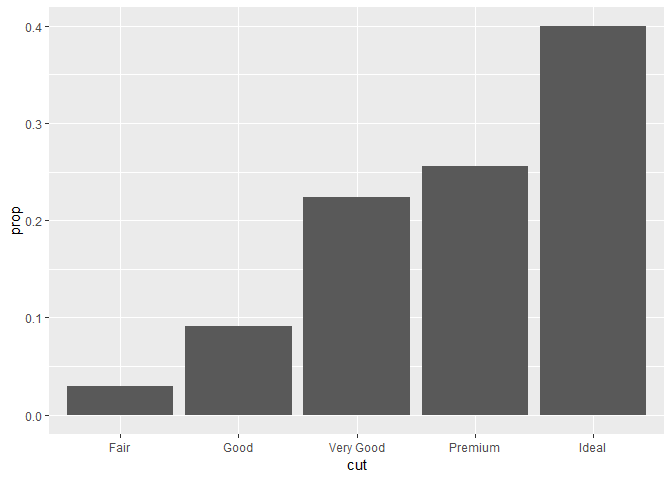
여기서 group = 1이 뭔지를 찾아봤는데, 이걸 추가 안하면 다음과 같이 나온다.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, y = ..prop..))
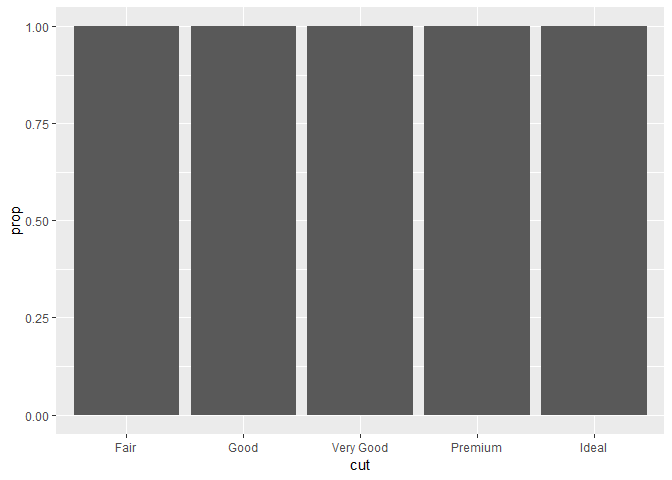
왜 이러냐면 Fair인 것들의 Fair 비율은 100%, Ideal인 것들의 Ideal 비율은 100% 이런 식이기 때문. 뭘 기준으로 prop(비율)을 계산할건지를 지정하는게, group = 1의 역할. 즉, x 변수인 cut을 기준으로 Fair가 몇 퍼센트인지, Ideal은 몇 퍼센트인지를 계산해라.하는 것. 그래서 다음과 같이 해도 된다.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, y = ..prop.., group = "x"))
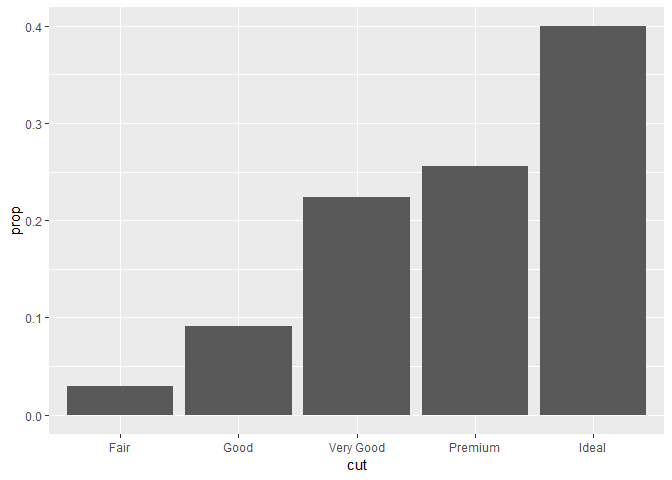
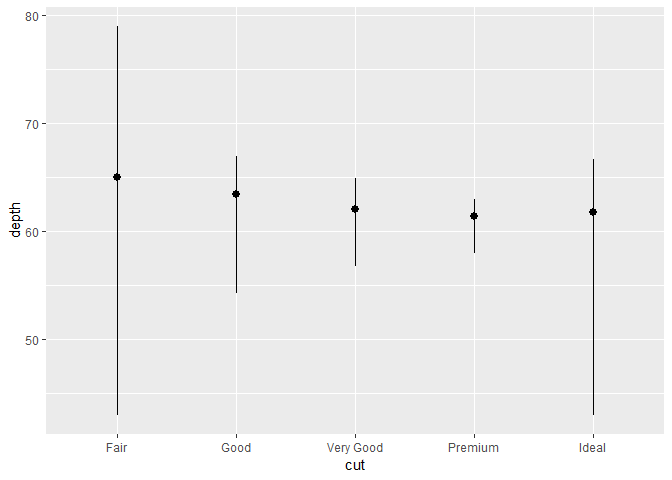
- 코드에 있는 statistical transformations가 좀 더 관심받도록 할 수도 있다. 예를 들어서,
stat_summary()를 이용하면, 각 unique한 x 값에 대해, y 값들을 요약summarise해준다.
ggplot(data = diamonds) +
stat_summary(
mapping = aes(x = cut, y = depth),
fun.ymin = min,
fun.ymax = max,
fun.y = median
)
 ggplot2는 20개가 넘는 stats들을 제공한다. 각 stat은 함수이기 때문에,
ggplot2는 20개가 넘는 stats들을 제공한다. 각 stat은 함수이기 때문에, ?stat_bin과 같은 방법으로 help를 얻을 수 있다. 모든 stats들 리스트를 보고 싶다면, ggplot2 cheatsheet를 확인해보자.