Introduction
R은 뼛속까지 함수형 언어functional language다.
이게 무슨 뜻이냐면, 분명 기술적인 특징technical properties이 있긴 하지만,
더 중요하게 함수를 중심으로 한 문제를 해결하는데 적합한 언어라는 것.
This means/ that it has certain technical properties, but more importantly / that it lends itself / to a style of problem / solving centred on functions.
아래에서 함수형 언어에 대한 기술적인 정의의 간략한 개요brief overview를 소개하긴 하지만,
이 책에서 나는 우선적으로 functional style of programming에 집중할 것이다.
왜냐하면 내가 생각하기에, 이 것이 data analysis를 하는데 있어
자주 만나는 문제들의 types를 해결하는데 매우 좋은 fit이 되기 때문.
최근, functional techniques에 대한 관심이 급증하고 있는데,
왜냐하면 이 것들이 현대 문제들modern problems에 대해 효율적이고 우아한 해결책들을 제공하기 때문.
functional style은 독립적으로 분석하기analysed in isolation에 좋은 함수들을 만든다.
그래서 optimise하거나 parallelise하기에 훨씬 쉽다.
함수형 언어의 전통적인 단점이었던,
떨어지는 퍼포먼스나 가끔 예견치 못한 메모리 사용은 최근 몇 년동안 많이 줄었다.
poorer performance and sometimes unpredictable memory usage
Functional programming은 Object-oriend programming(OOP)의 보완재complementary이다.
OOP는 최근 몇십년동안 지배적인 프로그래밍 패러다임.
Functional Programming Languages
모든 프로그래밍 언어는 함수들을 가지고 있다.
그럼 무엇이 프로그래밍 언어를 functional하게 만드는가?
정확히 무엇이 언어를 functional하게 만드는지에는 여러가지 정의들이 있지만, 2개의 공통점two common threads이 있다.
첫 번째, functional 언어는 first-class functions를 가지고 있다.
여타 다른 데이터 구조들과 똑같이 행동하는 함수들.
R에서는, 이 말인즉슨, 벡터로 할 수 있는 것들은, 함수를 가지고도 할 수 있다는 뜻이다.
변수에다가 할당assign할 수도 있고, 리스트에다가 저장할 수도 있고, 다른 함수에다가 인자arguments로 패스해 줄 수도 있다.
함수 안에다가 생성할 수도 있고, 심지어는 함수의 결과물로 return해줄 수도 있다.
create them inside functions, and even return them as the result of a function.
두 번째, 많은 함수형 언어들은 함수들이 pure하기를 요구한다.
다음 2가지 특성을 만족하면 함수가 pure하다고 한다.
-
output은 오직 inputs에만 의존한다.
즉, same inputs를 이용해서 다시 호출call해보면, 같은 outputs를 갖는다.
그래서runif(),read.csv(),Sys.time()과 같은, 다른 값들을 return하는 함수들은 제외된다. -
함수가 side-effects가 없어야 한다. global variable의 값을 바꾼다거나,
disk에다가 writing을 한다거나, 스크린에 displaying을 한다거나 이런게 없어야 한다.
그래서print(),write.csv(),<-같은 함수들은 제외된다.
pure 함수들은 이유를 따져보기에reason about 훨씬 더 쉽다. 하지만 상당한 단점significant downside이 있다.
data analysis를 하는데 random numbers를 생성할 수 없다거나, 디스크로부터 파일을 읽을 수 없다거나 하는 걸 상상해보라.
엄밀하게 말하자면, R은 functional programming language는 아니다.
왜냐하면 pure 함수들을 write하라고 요구하지는 않기 때문이다.
하지만, 분명히, functional style을 너의 코드에 적용시킬 수는 있다.
꼭 pure 함수들을 써야하는 것은 아니지만, 대부분의 경우 그래야 한다.
내 경험에, 코드를, 매우 pure한 함수들과 매우 impure한 함수들로 쪼개는 것partitioning이,
코드를 이해하기 쉽고, 새로운 상황에 확장시키는데 쉬웠다.
Functional style
functional style이 정확히 무엇인지 말하기describe는 어렵다.
하지만 내가 생각하기에 이건 큰 문제를 작은 조각들로 쪼개서,
각 조각을 함수나 함수들의 combination으로 해결하는 것.
functional style을 사용할 때는, 문제의 components를 분해decompose해서,
독립적으로 작동하는 독립된 함수들isolated functions that operate independently로 처리할 수 있도록 노력해야 한다.
자체적으로 수행되는 각 함수는 간단하고, 이해하기 쉽다.
Each function taken by itself is simple and straightforward to understand
복잡함은 함수들을 다양한 방법으로 쪼갬으로써 해결할 수 있다.
그래서, 이후의 3 chapters에서는 핵심 functional techniques를 다룬다.
문제를 작은 조각들로 쪼개는데 도와주는 것들.
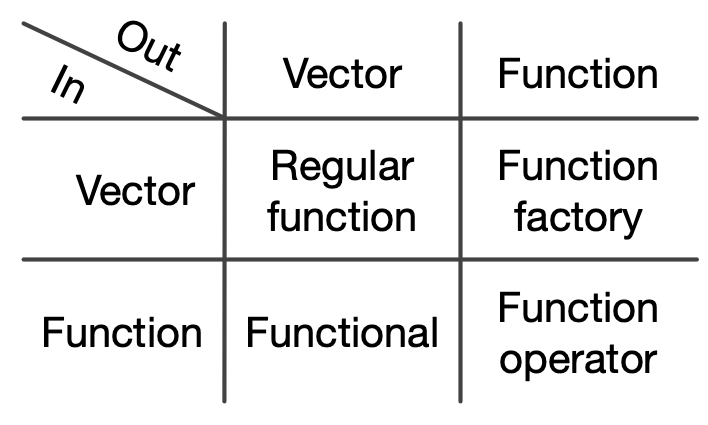
- Chapter 9는, 많은 for 루프문들을, functionals로 어떻게 대체할 수 있는지를 보여준다.
Functionals는 다른 함수를 argument로 받는 함수들.
Functionals는 함수를 받게 해준다. single input을 받아서 문제를 해결하는 함수.
그리고 이걸 inputs가 몇 개가 되든간에 가능하도록 일반화해준다.
Functionals는 매우매우 중요한 technique이며, data analysis를 할 때 항상 쓰게 될 것이다.
추가설명
지금은 뭔소리인가 하겠지만, 당장 다음 Chapter를 배우게 되면 그리 어려운 말이 아니다.
그래도 간단한 예를 소개해보자.
당장 다음 Chapter에 나오는 예를 해보자면,
## [[1]]
## [1] 3
##
## [[2]]
## [1] 6
##
## [[3]]
## [1] 9
\#\# \[\[1\]\]
\#\# \[1\] 3
\#\# \[\[2\]\]
\#\# \[1\] 6
\#\# \[\[3\]\]
\#\# \[1\] 9
원래 우리가 `triple()`이라는 함수를 `triple(1)`, `triple(2)` 이런 식으로 쓰던가, `lapply()`를 이용해서 쓰던가 했는데,
가장 먼저 배우게 될 functional인 `purrr::map()`을 통해서 inputs의 개수가 몇 개가 되든간에 일반화해서 가능하게 된 것.
-
Chapter 10은, function factories를 소개한다.
functions를 생성create하는 functions.
Function factories는 functionals보다는 훨씬 덜 사용되지만,
코드의 다른 부분 간에 작업을 우아하게 분할하게 해준다.
but can allow you to / elegantly partiton work / between different parts of your code. -
Chapter 11은, function operators를 만드는 걸 보여준다.
functions를 input으로 받아서, output으로 functions를 생산produce하는 functions.
부사adverb같은건데, 일반적으로 함수의 작동을 수정modify한다.
They are like adverbs, because they typically modify the operation of a function.
종합해서, 이러한 타입들의 함수는 higher-order functions라고 불리고, 2 by 2 테이블로 정리해보면,